2019-08-30 13:58:30 来源:中国网

微众银行作为联邦学习的国内首倡者和领导者,在杨强教授的带领下首次提出了“联邦迁移学习”,并通过领衔联邦学习国际标准(IEEE标准)制定、开源自研联邦学习框架Federated AI Technology Enabler(简称FATE)等来推动联邦学习技术在行业中的落地。
以下为微众银行首席人工智能官杨强教授演讲全文:
大家好,今天非常高兴跟大家讨论这样一个题目——人工智能最后一公里。为什么会起这样一个题目呢?现在我在微众银行负责人工智能的工作,接触到很多人工智能的应用场景。像微众银行这样一个互联网银行,它服务的用户数已经超过了1.7亿,提供服务主要借助的手段就是人工智能和机器人。在服务过程中有很多环节,比方说业务咨询、审核批准贷款文件、对申请人进行人脸识别、语音识别等身份核验、客服问答等。在金融领域,不仅要建立用户画像和模型找到用户,更要建立一整条长链路来服务广大的用户。
我们已经很熟悉这些人工智能领域的应用,但我想说的是,这些应用都离不开一个元素——数据,尤其是大数据。但是我们看看我们的周边,却发现数据非常有限。在法律领域,积累一条有效的数据是需要很长时间的;在金融领域,尤其是大额贷款、理财领域,有效的数据也是非常少的;在医疗领域面临的是数据割裂的现象,每个医院都有很多的医疗影像数据,却出于监管、安全、利益等原因不能够互相传递,无法形成合力。
在这种情况下,数据聚合的需求十分强烈,却很难得到满足。其中有一个很重要的原因是社会对于用户隐私的要求越来越高。现在世界各地的监管机构纷纷出台强有力的法规,比方说欧盟在去年正式提出《通用数据保护条例》(GDPR),对个人隐私、个人数据的拥有权,包括模型的使用和可解释性都提出了非常严格的要求。中国的法律也在快步推进,连续出台了一系列关于用户隐私、用户数据安全和拥有权的法规,也将会严格限制企业之间的数据交换。
我们一方面面临数据割裂,没有大数据来训练人工智能;另一方面,法律法规和社会对安全的严格要求又限制了数据的融合。大数据变成了人工智能的挑战。
我们如何应对这个挑战?放弃人工智能吗?仅允许拥有大数据的公司来做人工智能吗?这都不对,我们的回答是,要积极地寻找一些新的技术方向来解决数据挑战。
我们提出的方法和方向叫做“联邦学习”,英文叫“Federated Learning”。数据的各个拥有方,在各自数据不出本地的情况下建立模型,并且让这个模型能够共享,那么在建立模型的过程中便不会侵犯用户的隐私,整个建模的过程就叫联邦学习的框架和算法。
Google在2016年就开始进行一个项目,在安卓系统的手机用户中建立联邦学习,解决用户个人终端设备的数据隐私问题。首先初始化模型下载到各终端,各终端根据自己本身的数据更新模型参数,不同的终端就会产生不同的更新结果,这些更新被送到云端进行聚合,汇总后的模型参数将作为下一次更新的初始参数,这样一直迭代直到收敛。用这样的一个方法既能保证用户隐私,同时又能共享一个通用模型,利用群体智能在云端不断更新。
这样的模型不仅需要一个机器学习算法,更需要一个分布式的机器学习算法。在分布式的机器学习算法之上,还要有各种加密的算法。在这个基础上,我们仔细地分析了一下,发现一共有三种模式来进行联邦学习。
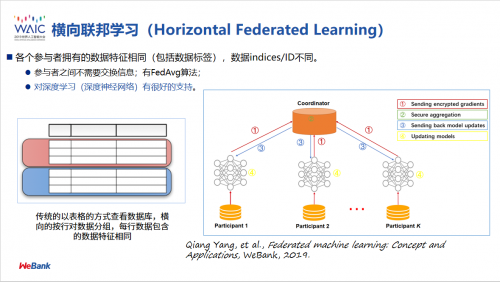
第一种模式叫横向联邦学习,是指当两个数据集的用户不同,重叠较少,但用户特征重叠较多时,我们把数据集按照横向 (即用户维度) 切分,并取出双方用户特征相同而用户不完全相同的那部分数据进行训练。
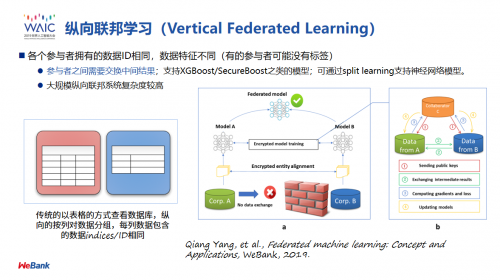
第二种叫做纵向联邦学习,是说两个数据集的用户特征重叠较少,但它们却有较多的重叠用户,那么我们就把数据集按照纵向 (即特征维度) 切分,并取出双方用户相同而用户特征不完全相同的那部分数据进行训练。
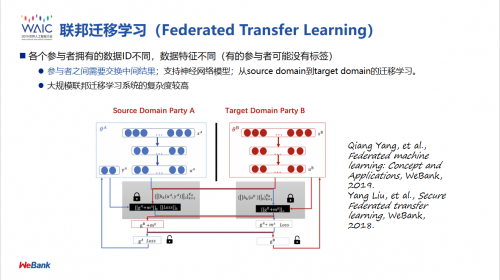
最后,如果两个数据集既不重叠用户特征,又不重叠用户,那么在这个场景下,我们也提出一个新的算法,叫做联邦迁移学习。它可以利用迁移学习的算法,把这两方数据模型的本质挖掘出来,把抽象的模型加以聚合,在聚合的过程中保护用户隐私,也取得非常大的成功。
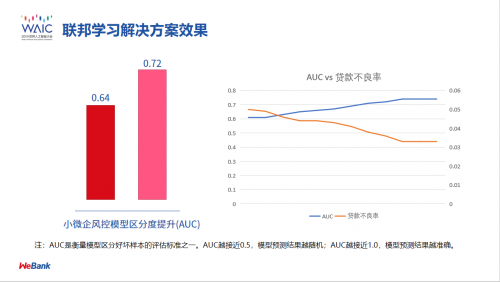
虽然联邦学习的框架最近才提出来,但是它在产业界的应用已经有成熟的进展。比方说我们最近在一个金融信贷的场景下就取得了非常成功的应用:一方是互联网企业,有很多用户的行为数据;另一方是金融企业——银行,需要建立一个更准确的用户信贷模型。这时利用纵向联邦学习,把两边的模型加以共享,进行更新,这样模型就能够更有利,随着数据量的增加,效果也大为增加。以下是效果图。
同时,我们也尝试了很多不同的应用场景,比方说在城市管理领域,利用散落在各地的割裂的计算机视觉数据来建立一个安全、共享的模型;在语音识别领域,不同的机构有不同的语音数据,不同的服务中心,它们也可以建立一个联邦学习来解决用户隐私的问题。
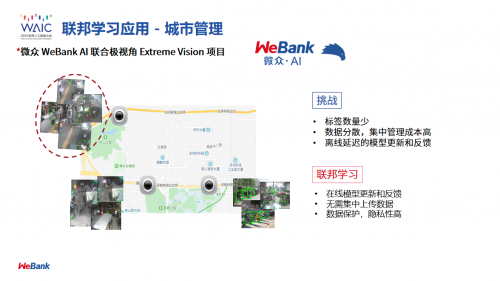
刚刚讲的这些应用都离不开一个概念,叫做生态。联邦学习生态的建立需要我们不断地去倡导。我们在学术界和工业界也做了一系列的推动工作,包括在刚刚结束的第28届国际人工智能联合会议(IJCAI 2019)上举办了首届国际联邦学习研讨会;在Linux Foundation开放了全球首个联邦学习的开源项目,叫FATE(Federated AI Technology Enabler),和更多的开发者一起为联邦学习开源做出积极贡献。同时,我们也正在建立一个联邦学习国际标准(IEEE标准),让不同的机构之间可以有共同的语言,在建立联邦学习共同模型的时候大家的沟通会更敏捷;在国内,我们也取得了很大的成就,牵头建立国内首个关于联邦学习的团体规范标准——《信息技术服务 联邦学习 参考架构》团体标准。
最后,机器学习离不开大数据,大数据离不开安全和保护隐私的考虑。联邦学习是一个既能建立大数据模型,又能保护数据安全和用户隐私的有利的工具,希望更多的人能加入我们一起建立联邦学习生态。谢谢大家!
详细了解联邦学习:
官网:fedai.org
开源项目FATE:https://github.com/webankfintech/fate
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




