2020-03-27 18:10:11 来源:互联网
无论它身在哪个行业
总会让人们发出惊叹:
AI打败排名世界第一的围棋选手,WOW!
AI能帮你驾驶汽车,Awesome!
AI能诊断疾病,Niubility!
在这个言高科技必称AI的年代,AI在大众的印象里总是遥远而神秘,但小编要告诉你,其实AI并不遥远~
今天,我们邀请到戴尔易安信非结构化数据解决方案企业技术顾问简君芳,教你如何手动搭建一个AI算法模型。动动手,你也可以亲自实践AI。
简单深度学习实践
搭建猫狗识别AI算法模型
开始前,首先介绍一下AI的工作流程:
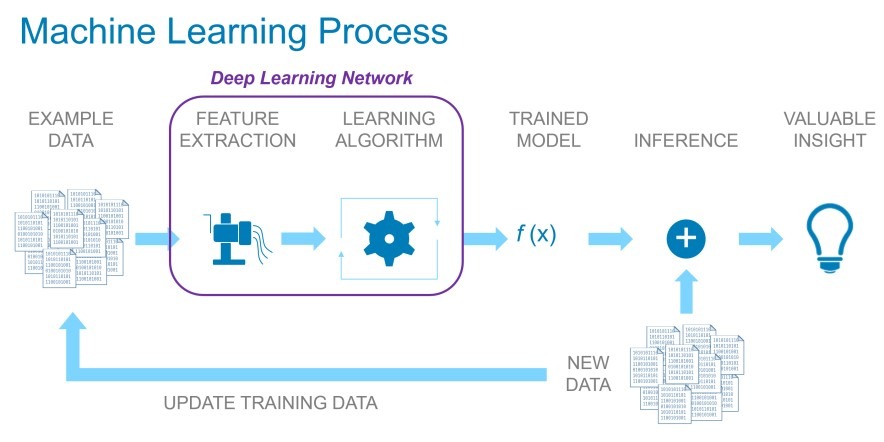
简单来说就是分成两部分:
1.训练
①需要累积数据,并预期数据越多越好,所以存储必须可扩展。
②数据科学家处理数据,初步建立算法模型,读取数据。
③需要GPU执行framework(如TensorFlow),forward前向传播跑出结果,计算误差损失,backward反向传播更新参数修改模型,不断重复, 最终得到准确度较高的训练好的模型。
2. 推断
①需要全新的数据来验证。
②使用训练好的模型,验证准确度是否真的够高。
③部署该模型到实际环境正式使用。
这其实是一个永无止尽不断循环的过程,没有最好的模型,只有更好的模型。总之,目的就是要找出可以帮助公司业务,达到最佳ROI的“那个模型”。但重点是,要怎么找到“那个模型”,够好还有够快?这才是AI时代,各公司真正的核心竞争力所在。
所以现在就要来好好分析一下这个过程的三大要素:
1. 大数据
有人说过,若你有趋近无限的数据,你就可以训练出趋近完美的模型。所以要模型好,准确度高,最重要的就是先要有数据,越多越好。不过这首先就会带来一个问题,这些不断成长数据要放在哪里?本地磁盘容量不够,RAID存储扩充不行,只有真正分布式的横向扩展存储才是最适合大数据的,从而让模型更好。

2. 算力
比如GPU,计算力越强,AI流程越快,也是基础设施成本最贵的部分。可是并非花了大价钱买了GPU,就能高枕无忧了,如果GPU的使用率只有不到50%呢,这样还快得起来吗?
事实上这是目前非常普遍的现象,GPU使用率不高的原因通常都是在于I/O瓶颈。而只有可以分散处理大量并发I/O的分布式存储才是最能提高GPU利用率的,让模型更快。

3. 算法
算法需要数据科学家一方面了解公司业务,另一方面了解数据,建立正确的模型。
说的简单,其中过程也是非常复杂的,比如IoT需要使用Kafka,机器学习需要使用SparkML,深度学习需要使用TensorFlow,大数据分析需要使用Hadoop,处理数据需要使用ETL工具,最后还要做可视化/BI等……若都是分开的孤岛,不但流程复杂,数据需要复制许多份,并且数据迁移来迁移去非常耗时。
这时候不如使用数据湖,不再有孤岛,整合流程,数据保持同一份节省TCO整体成本,省下数据迁移的心力,提升数据科学家的工作效率,让他们专注在最有价值的算法上。

接下来,就用实际的猫狗辨识简单实践来体验一下TensorFlow深度学习吧!
这里我使用的存储是戴尔易安信Isilon,为什么用它呢?通过上面的讲解你应该能知道,AI所需要存储不仅要强大扩展能力,同时还不能有I/O瓶颈。而Isilon正是一款真正分布式的横向扩展NAS存储,不仅能轻松扩展到数十个PB,还能助攻GPU,让使用率高达90%+,更能提供原生数据湖整合流程提升工作效率。

*Isilon由英特尔® 至强®处理器提供支持,该处理器采用软件定义的基础设施和敏捷云架构,为Isilon提供了卓越的性能和效率,可加速要求严苛的文件工作负载,使企业发挥数据资本的价值,加速业务的数字转型。
广告不多说了,下面正式开始实践。
这里我使用VMware Workstation跑两个VM:
一个VM是Ubuntu 16.04作为AI服务器,安装软件如下:
☞ Anaconda with Python 3.7
☞ Jupyter Notebook
☞ TensorFlow
☞ Keras
☞ Opencv
另一个VM是Isilon simulater OneFS 8.2.0作为AI存储,设定准备如下:
☞ 启动trial license
☞ 建立/ifs/ai路径
☞ 在网络上下载了三千张猫跟狗的图片数据,都放在/ifs/ai/datasets/images目录下
☞ 在网络上下载了深度学习猫狗辨识模型的python code,路径为/ifs/ai/dl_isilon.ipynb
☞ 建立/ifs/ai/trained_模型s目录给训练好的模型存档
01 步骤一
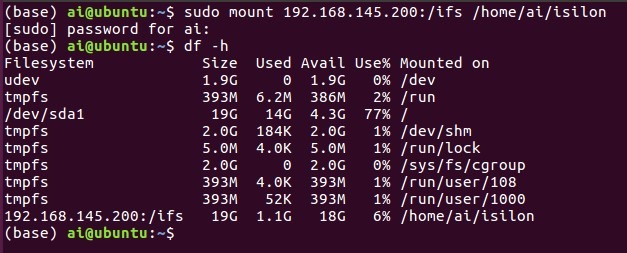
建立联机,正式环境可能会使用Kubernetes,可以把Isilon直接用NFS或是透过CSI作为persistent volume提供给GPU docker。但因为我这里只使用单一VM,所以我用最简单的NFS mount方式,把Isilon mount给Ubuntu的/home/ai/isilon目录。
02 步骤二
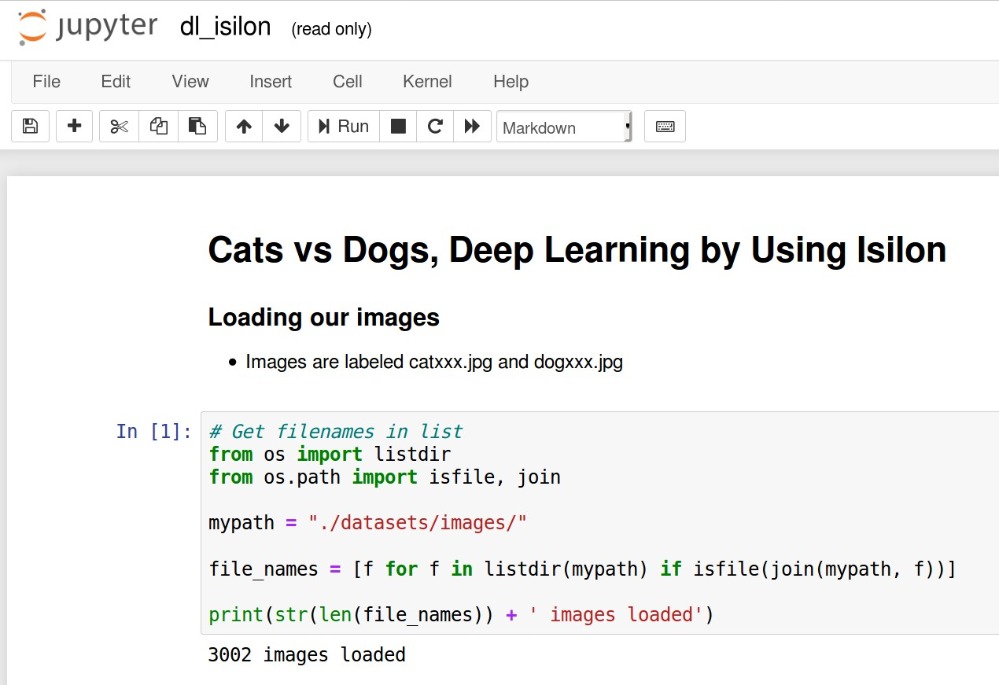
接着在Ubuntu上开启Jupyter Notebook,这时候可以看到名为isilon的目录出现,进入/Isilon/ai就可以看到之前准备好的数据和python code。

03 步骤三
打开dl_isilon.ipynb,一开始就是要设定读取数据的地方,这里的路径“./datasets/images/”其实就是指向Isilon的/ifs/ai/datasets/images。
04 步骤四
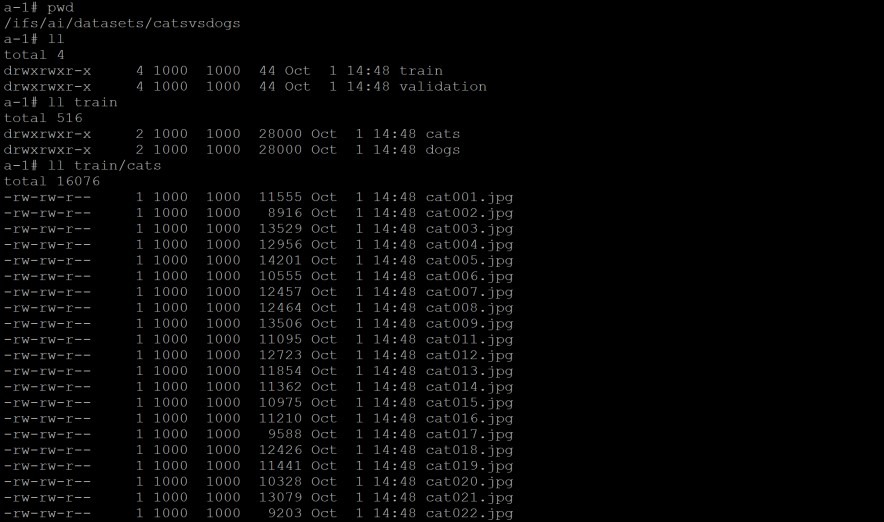
接下来把三千张图片重设大小,做卷标分类,其中两千张来做训练,一千张做验证,于是会产生四个目录,其中“./datasets/catsvsdogs/train/dogs”其实就是指向Isilon的/ifs/ai/datasets/catsvsdogs/train/dogs,依此类推。

05 步骤五
然后经过一些转格式的预处理动作,就是建立CNNmodel的部分了,其中有些超参数可以调整如batch_size,epochs。



现在就开始训练了,训练好的模型会存档为./trained_models/cats_vs_dogs.h5,其实就是指向Isilon的/ifs/ai/trained_models/cats_vs_dogs.h5。
可以看到,训练十次,每次两千张,损失越来越低,准确度越来越高,训练第一次的准确度只有50%,训练第十次的准确度有71.5%,当然这远远不够高, 是因为只有两千张图片,想象一下若有两万张图片,准确度就可能到达95%以上了,这就是大数据的威力与价值!
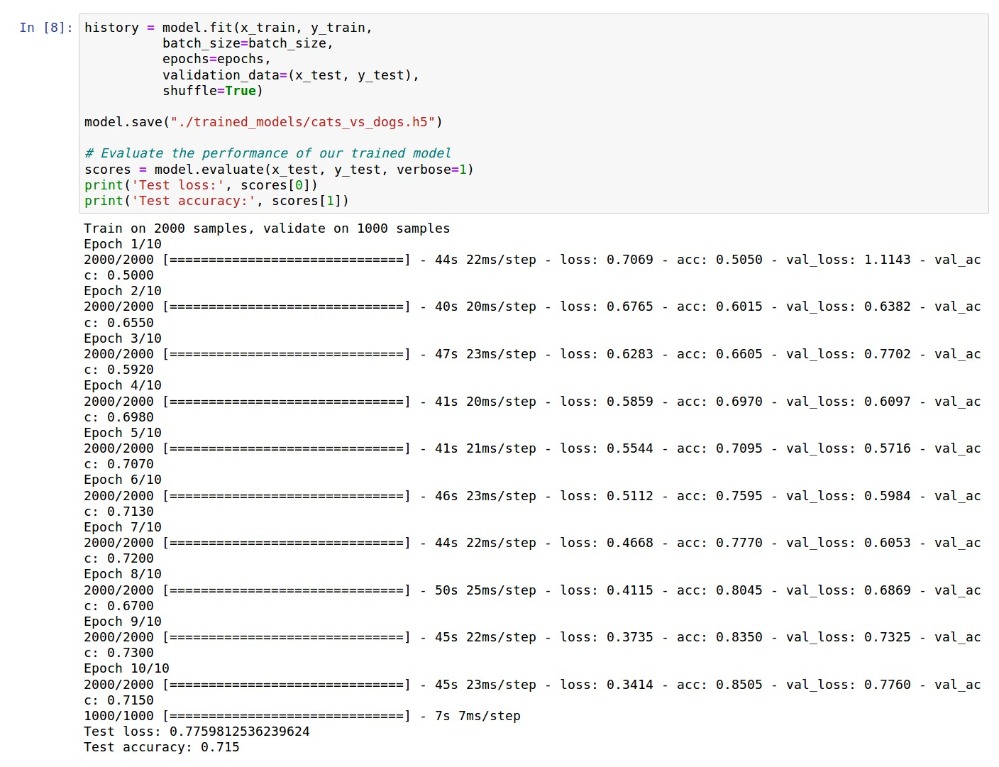

接下来用另外一千张图片来验证这个已经训练好,存在Isilon上的模型。

以上就是一个简单的使用Isilon实现AI解决方案的猫狗辨识实践。其实AI并没有那么神秘,动手起来也不难,最重要的,是不是觉得Isilon真的很适合AI了呢?
如果这个训练好的模型准确度高于人类,那么就可以实际部署在生产环境上了,以后就可以让AI帮助公司业务来判断图片,比人类准确度高,比人类速度快,还不会有人为错误,一片美好的未来~

但是!工欲善其事,必先利其器,必须要先有适合的AI存储如Isilon才能往美好的未来迈进,准确并快速地找出可以高效帮助公司业务的模型,达到最佳ROI!

免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




