2021-11-24 17:55:37 来源:
该研究工作已被 ICCV(计算机视觉领域最负盛名的会议之一)接受为演讲报告。 这种新方法在 10 月 11 日至 17 日在线举行的ICCV 2021会议上进行了介绍。 https://iccv2021.thecvf.com/home
根据用于获取物体周围 3D 信息的传感方法,SLAM 可以分为两种主要类型。 一种是 LiDAR(光探测和测距),它使用激光测量距离。 另一种是Visual SLAM,它使用相机图像。 视觉 SLAM 正在显着发展,因为所使用的相机相对便宜,并且除了同时定位之外,还可以将该方法与使用图像识别的各种控制过程相结合,从而可以期待许多应用。
近年来,随着深度学习的引入,图像识别技术取得了显著的进步,深度学习的应用成为了视觉SLAM演进的重要因素。 然而,基于特征点和相机方向优化地标的未知 3D 信息的束调整(BA)所需的大量计算是传统方法的瓶颈。 对于 CPU 处理能力有限的边缘型 SoC 设备,这会使实际处理变得困难。
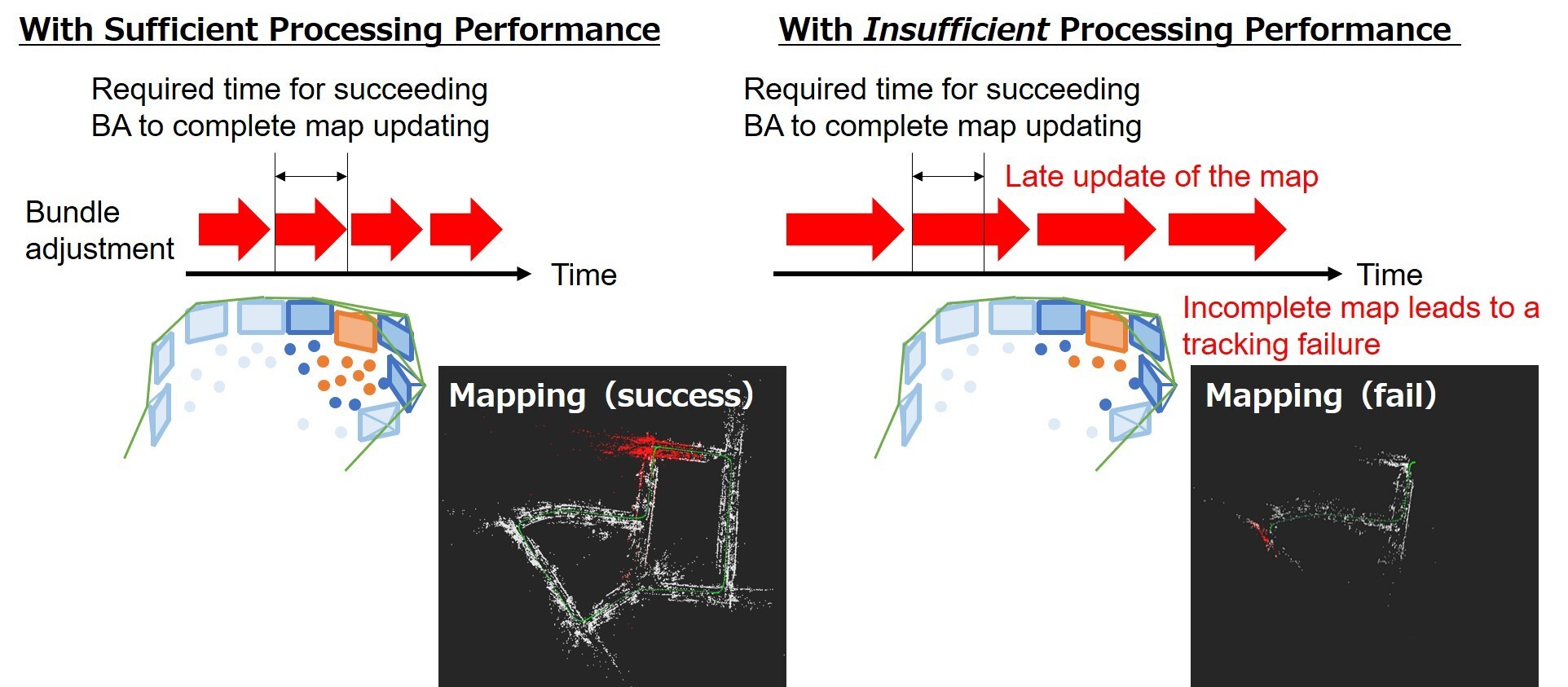
(图1)
为了应对这一挑战,研究团队提出了一种使用“图网络(GN)"[1] (一种图神经网络)通过推理进行近似计算的方法。 新方法包括从 GN block输入的关键帧和地标信息中推断更新信息(图 2),并通过多堆栈 GN 结构收敛到最终值(图 3)。 与使用传统 Levenberg-Marquardt 方法的标准束平差相比,这些使得推理处理所需的计算量更少。
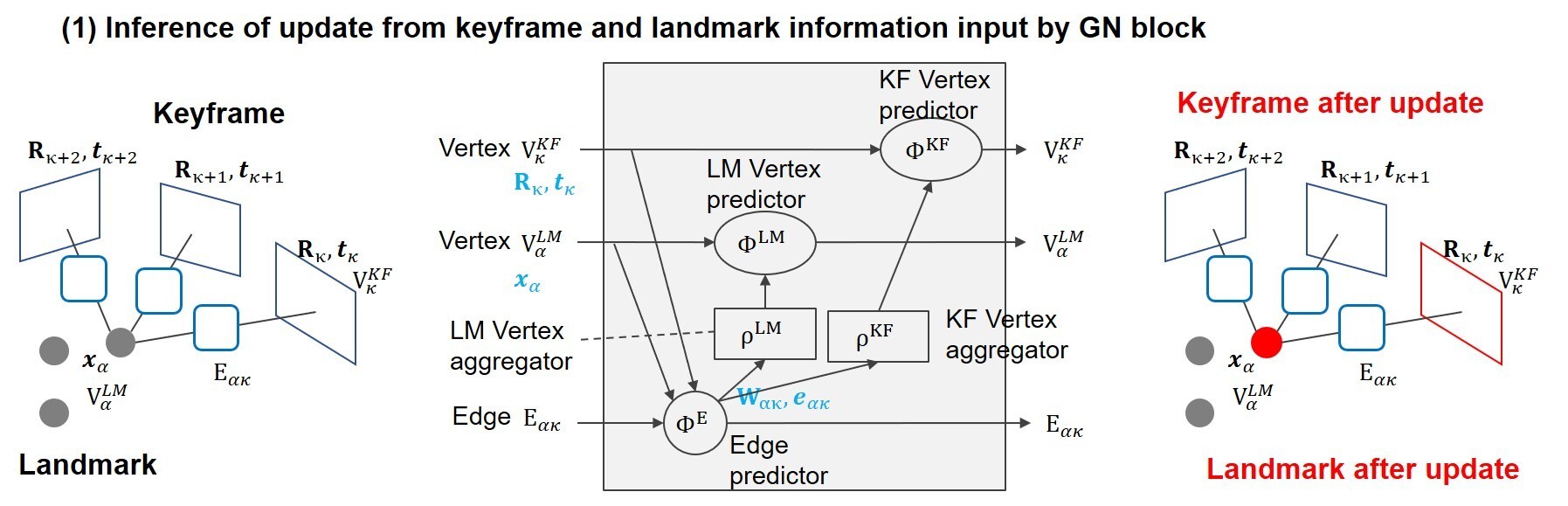
(图2)
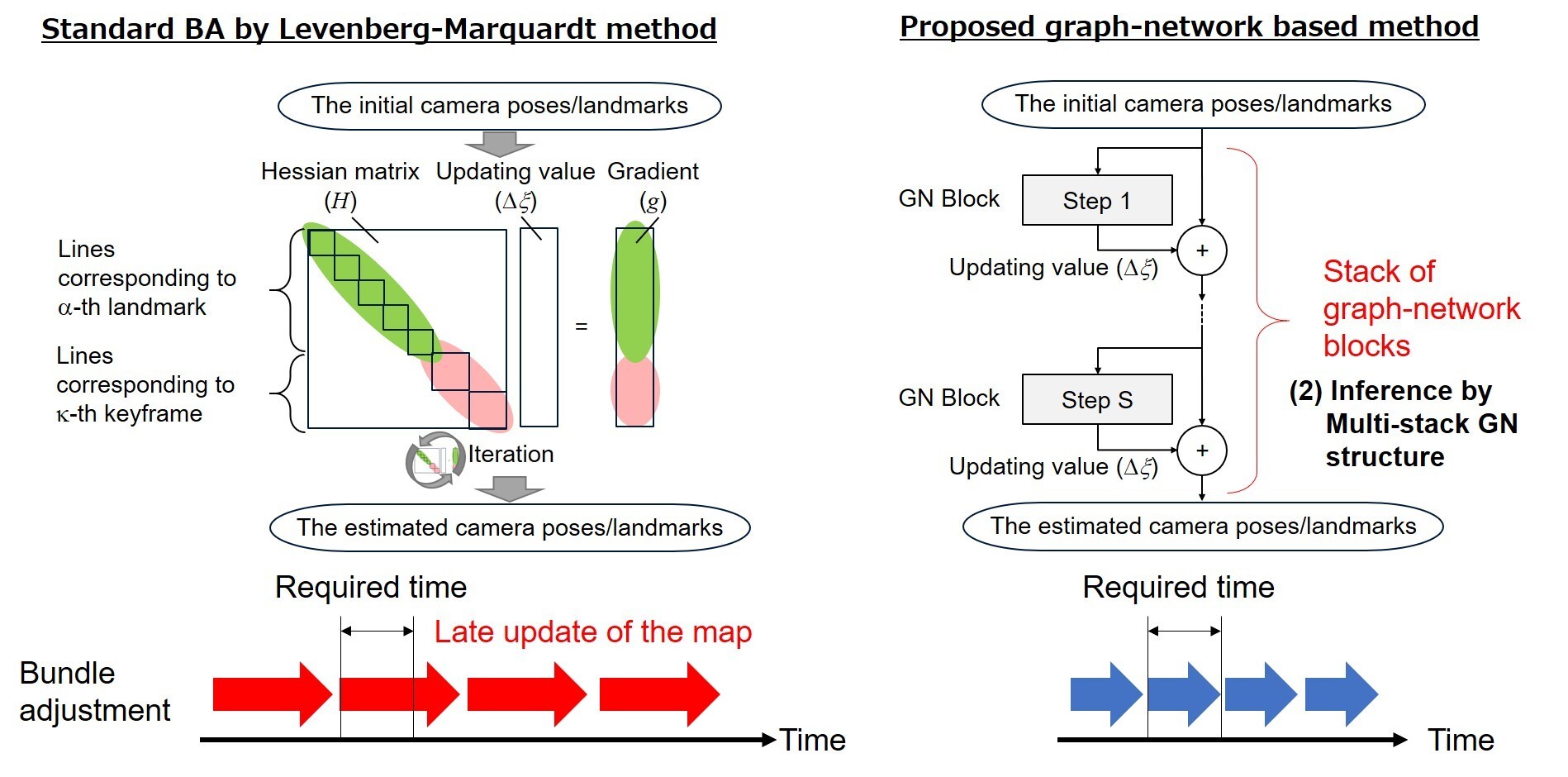
(图3)
研究团队使用这种新的推理方法实现了 Visual SLAM 捆绑调整,并将其与当今广泛使用的方法“g2o”[2]进行了比较。 PC 仿真结果证实,与 g2o 相比,新方法可以将处理时间缩短至 1/60。(图 4)
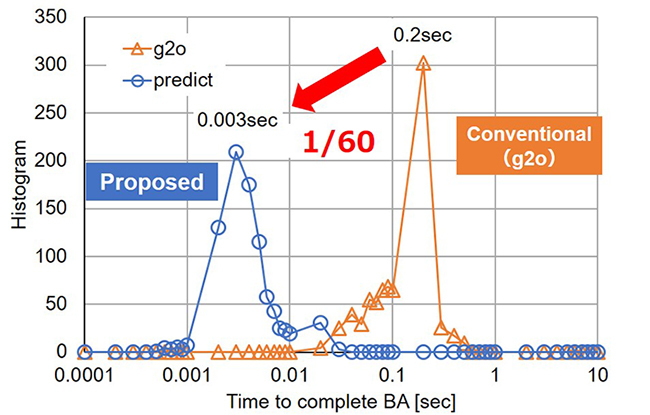
(图4)
Socionext 将从这项研究工作中积累经验,并将 Visual SLAM 技术确立为公司定制 SoC 解决方案的产品之一。 该公司将为工业设备和移动等需要图像识别领域的客户系统提出创新的性能改进方案。 此外,公司将继续研发通过新的推理方法提高处理效率,并将其使用扩展到图像识别以外的新客户应用。
作者:
Tetsuya Tanaka, Yukihiro Sasagawa from Socionext, and Takayuki Okatani from Tohoku University
主题:
Learning to Bundle-adjust: A Graph Network Approach to Faster Optimization of Bundle Adjustment for Vehicular SLAM
注释:
[1] “关系归纳偏差、深度学习和图网络”来源自: https://github.com/deepmind/graph_nets, Battaglia et al.
[2] “G2o: 图形优化的通用框架”
来源自: 2011 IEEE International Conference on Robotics and Automation, Kmmerle et al.
关于Socionext Inc.
Socionext Inc.是一家全球性创新型企业,其业务内容涉及片上系统(System-on-chip)的设计、研发和销售。公司专注于以消费、汽车和工业领域为核心的世界先进技术,不断推动当今多样化应用发展。Socionext集世界一流的专业知识、经验和丰富的IP产品组合,致力于为客户提供高效益的解决方案和客户体验。公司成立于2015年,总部设在日本横滨,并在日本、亚洲、美国和欧洲设有办事处,领导其产品开发和销售。
更多详情,请登录Socionext官方网站:http://www.socionext.com。
本新闻稿中提及的所有公司或产品名称均为其各自所有者的商标或注册商标。以上发布的信息为截止发稿时的 信息,日后若发生变更,恕不另行通知,敬请谅解。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




