Tigerbot是虎博科技自研的多语言多任务大规模语言模型,致力于改善人们的工作流以提高效率,将成为人们工作必备的外脑搜索引擎之一。参与评测的TigerBot-7B是其第一版MVP,经历了3000次实验迭代。目前,虎博科技创始人兼CEO陈烨持续带领团队改进,已迭代出同等大小且表现优于OpenAI的新模型,并将在近期更新发布。(产品体验:https://www.tigerbot.com/chat,登录即可申请体验,感受逼近OpenAI表现的国产大模型。)
根据OpenAIInstructGPT论文在公开NLP数据集上的自动评测,TigerBot-7B已达到OpenAI同样大小模型的综合表现的96%,这得益于虎博科技在GPT和BLOOM基础上,对模型架构和算法进行了多项创新优化,包括指令完成监督微调的创新算法,以提升可学习型;运用ensemble和probabilisticmodeling的方法,实现更可控的事实性和创造性;在并⾏训练上,突破了deep-speed等主流框架中若⼲内存和通信问题,使得在千卡环境下可实现数⽉⽆间断等。此外,经对中⽂语⾔的更不规则的分布,虎博科技从tokenizer到训练算法等方面做了针对性算法优化,使得模型的问答更具中国文化属性。
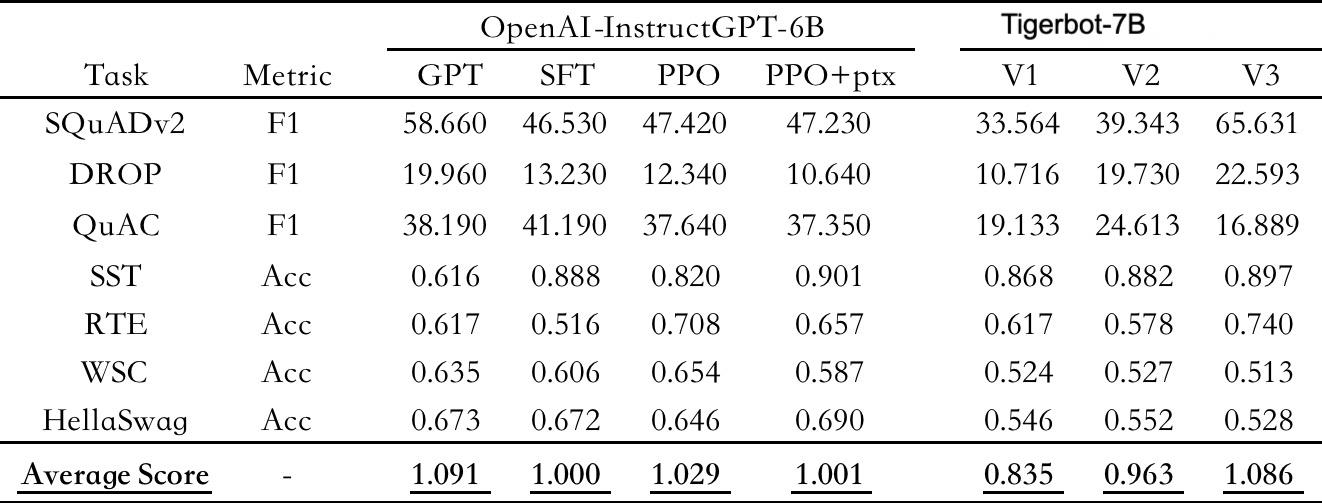
(上图为公开NLP数据集上的自动评测,以OpenAI-instructGPT-6B-SFT为基准,归一化并平均各模型的得分情况)
“此等一生难遇一次的大机遇,是吾辈之幸事!”在人工智能领域从业20年后,陈烨对大模型的横空出世发表了真挚的言辞,更激发了他内心年少时的激情。他认为,推进人类文明的技术变革往往源于本能、直觉和偶然性,而拥有自由的创新精神是根本。大模型技术就像是一门新兴学科,其未来的可能性将超过每个人的想象,他表示,现阶段过早和过于理性地探讨产品、应用、场景和商业化或许没有必要,更重要的是推广这一人工智能基础设施的原创突破,促进技术的发展和更新。“它将是颠覆式且长周期的。”
秉持科学创新无国界、无阶层的信念,虎博科技将以全套API形式开源Tigerbot的阶段性成果,试图与广大大模型应用开发者共同构建大模型生态蓝图,通过生态的发展反哺促进大模型能力迭代,让技术和产业发展共荣共生,共同打造中国的世界级应用。此次开源内容包含模型、代码、数据三部分,包含TigerBot-7B-sft、TigerBot-7B-base、TigerBot-180B-research等多个模型版本,经基本训练且覆盖双卡推理180B模型的量化和推理代码,以及高达100G的预训练数据和监督微调1G或100万条数据。值得一提的是,TigerBot-7B-base的综合表现优于同等可比的OpenAI和BLOOM,TigerBot-180B-research的参数量达1800亿,或是目前业内最大的大规模语言模型,而高达100G的预训练数据,更被视为目前业内最大且质量最优的开源预训练数据之一。同时,虎博科技还将开放大量的金融、法律、百科等领域专业数据,供应用开发者使用。(开源地址:https://github.com/TigerResearch/TigerBot)
回顾Tigerbot研发过程,虎博科技致敬了硅谷90年代经典的“车库创业”模式,项目组在陈烨的带领下,从5人小队发展成目前10人小组。团队克服多重困难,在1月内实现自研全栈代码,当时测试表现已达OpenAI可比模型的80%效果,为整个团队注入了一剂“强心针”,促使他们不断突破事实性、创造性和思维链等底层研究,最终实现了算法、工程、数据的高效迭代。他们以每日至少3次,累计超过3000次的实验,打造出了Tigerbot。
据悉,虎博科技成立于2017年,以让人们获取知识更简单为愿景,致力于通过深度学习、自然语言处理等世界前沿技术,深入挖掘全球各行业信息,以可视化的问答方式呈现关键内容。同时,以贴近一线的视角精准洞察行业痛点,将核心技术产品化,帮助企业在日常运营、产品体验等多方面高度提效。截至目前,虎博科技融资额超越同阶段AI+NLP领域其他企业。




