有研究表明,人工智能听上去很厉害,但目前最先进的人工智能还远远不能解决人类 4 岁儿童能够轻松解决的问题,那么,人工智能会变得比 4 岁的孩子更聪明吗?看看孩子们如何处理信息如何学习的,大家或许能获得启发。
每个人都听说过人工智能的新进展,尤其是机器学习,尽管人工智能的名称令人印象深刻,但该技术在很大程度上是由检测大数据集中的统计模式的技术构成的,人类的学习方法可远不止于此。
人类是如何学习的
我们是怎么对我们周围的世界了解得这么多的呢?即使还是儿童的时候,我们也能学到很多的东西,比如四岁的孩子已经知道植物、动物和机器;欲望、信念和情感;甚至恐龙和宇宙飞船。
科学已经把我们对世界的认识扩展到不可想象的地步,扩展到宇宙的边缘和时间的开始,我们用这些知识进行新的分类和预测,想象各种新的可能性,并在这个世界促成新的事情的发生,但触及这个世界的只是一股触及我们视网膜的光子流以及干扰耳膜的空气,当我们拥有的例证如此有限的时候,我们是如何用眼睛后面的几磅灰色黏液来完成这一切的呢?
到目前为止,最好的答案是,我们的大脑基于触达我们各种感官的具体特定而又混乱的数据进行运算,然后那些运算产生了对世界的准确描述,表现形式似乎是结构化的、抽象的和层次化的,它们包括对三维物体的感知,构成语言基础的语法,以及“心智理论”等心智能力。
“心智理论”能让我们理解他人的想法,这些表现形式使得我们能够做出各种各样的新预测,并以人类特有的创造性方式想象出许多新的可能性。
这种学习不是唯一的一种智力形式,但对人类来说尤其重要,这种智力是小孩子的专长,尽管孩子们在计划和决策方面非常糟糕,但他们是世界上最好的学习者,事实上,很多将数据转化为理论的过程发生在我们五岁之前。
人类两种基本的学习方法
自亚里士多德和柏拉图以来,有两种基本的方法来解决我们如何知道我们所知道的东西的问题,它们仍然是机器学习的主要方法。
亚里士多德自下而上来解决这个问题:从感觉开始——光子流和空气振动(或数字图像或录音的像素或声音样本),这样看你能否从中发现学习模式,这种方法被像哲学家大卫·休谟(David Hume)和密尔(J. S. Mill)这样的古典联想主义者以及后来的像巴甫洛夫(Pavlov)和斯金纳(B. F. Skinner)这样的行为心理学家进一步发扬。从这个观点来看,表现形式的抽象性和层次性结构是一种错觉,或者至少是一种附带现象,所有的工作都可以通过关联和模式检测来完成,特别是如果有足够数据的话。
这种自下而上的学习方法和柏拉图的自上而下的学习方法一直共存,谁也无法一直压过对方。
也许我们从具体的数据中获得抽象的知识,是因为我们已经知道了很多的东西,特别是由于进化,我们已经有了一系列基本的抽象概念。像科学家一样,我们可以用这些概念来构建关于世界的假设,然后,如果那些假设是正确的,我们就可以预测数据应该是什么样的,而不是试图从原始数据中发现模式,与柏拉图一样,笛卡尔(Descartes)、诺姆乔姆斯基(Noam Chomsky)等“理性主义”哲学家和心理学家也采取了这种方法。
有一个日常例子可说明上述两种方法之间的差异,它就是解决垃圾邮件泛滥的问题,那些邮件数据由收件箱中长长的未分类的消息列表组成,现实情况是,其中一部分邮件是非垃圾邮件,一部分是垃圾邮件。如何使用数据来区分它们呢?
先来考虑自下而上的方法,你会注意到,垃圾邮件往往有一些特征:长长的收件人列表,发送自尼日利亚,内文提及百万美元奖金或者壮阳药,问题是,完全有用的非垃圾邮件也可能具有这些特征,如果你看了足够多的垃圾邮件和非垃圾邮件的例子,你可能会发现垃圾邮件不仅往往具有这些特征,这些特征还往往以特定的方式出现在一起(尼日利亚来源以及提及 100 万美元奖金意味着有问题)。
事实上,可能有某种微妙的更高级的相关性可用来将垃圾邮件与有用的非垃圾邮件区分开来——例如,拼写错误和 IP 地址比较特殊,如果检测到那些特殊的模式,就可以过滤掉垃圾邮件。自下而上的机器学习技术正是这样做的,学习者会得到数百万个例子,每个例子都有某些特征,每个例子都被标记为垃圾邮件(或者其他的类别),计算机可以提取出区分二者的特征的模式,即便那些特征非常微妙。
那么自上而下的方法呢?举例来说,你收到了一封来自《临床生物学杂志》编辑的邮件,它谈到你写的其中一篇论文,说他们想要发表你的一篇文章,邮件来源不是尼日利亚,内文也没有提及伟哥和百万美元奖金,该邮件没有垃圾邮件的任何特征,但通过使用已有的知识,并以一种抽象的方式思考产生垃圾邮件的过程,你可以断定这封邮件是可疑的:
1. 你知道垃圾邮件发送者试图利用人类的贪婪从人们身上榨取钱财。
2. 你还知道,正规的“开放获取”期刊已经开始通过向作者而非订阅者收费来覆盖它们的成本,你也不从事临床生物学之类的工作。
综合所有的这些因素来看,我就可以提出一个关于邮件来源的新假设,它的目的是诱使学者付钱在假期刊上“发表”一篇文章,这封邮件和其他的垃圾邮件一样,都源自于可疑的形成过程,尽管它看上去一点也不像垃圾邮件,你可以从一个例子中得出这个结论,你可以跳出邮件本身,通过谷歌搜索发来邮件的编辑的信息来进一步验证你的假设。
用计算机术语来说,你是从一个“生成式模型”着手,它包括贪婪和欺骗等抽象概念,且描述了垃圾邮件的产生过程,这让你能够辨别典型的来自尼日利亚的垃圾邮件,但同时也让你想象到许多不同种类的潜在的垃圾邮件,当你收到来自《华尔街日报》的邮件时,你可以逆向推断:“这看起来就像那种从垃圾邮件生成过程中生成的邮件。”
人工智能新的令人兴奋之处在于,人工智能研究人员最近开发出了这两种强大而有效的学习方法,但评论认为,这些方法本身并没有什么新的深刻的东西。
自下而上的深度学习
在 20 世纪 80 年代,计算机科学家发明了一种巧妙的方法来让计算机检测数据中的模式:链结式(或称神经网络)架构。这种方法在上世纪 90 年代陷入低潮,但最近随着谷歌旗下 DeepMind 等强大的“深度学习”方法的崛起,它又重新焕发了生机。
例如,你可以为一个深度学习程序提供一组标记为“cat”(猫)、“house”(房子)等等的网络图像。该程序能够检测区分这两组图像的模式,并使用这些信息正确地标记新的图像。
被称为非监督式学习的机器学习技术能够从没有标记的数据中检测出模式;它们就是去寻找一组特征——科学家称之为因素分析。在深度学习机器中,这些过程在不同的层级上重复,有些程序甚至可以从像素或声音的原始数据中发现相关的特征,例如计算机可能首先检测原始图像中对应于边和线的的模式,然后在这些模式中找到对应于脸的模式,诸如此类。
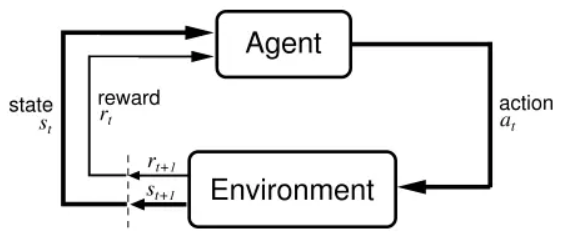
另一种历史悠久的自下而上的技术是强化学习。在 20 世纪 50 年代,斯金纳(B. F. Skinner)在约翰·沃森(John Watson)的研究基础上,通过给鸽子安排特定的奖惩活动,控制鸽子去执行复杂的动作——甚至指示空射导弹射向目标。其基本理念是,鸽子得到奖励的行为会重复,而受到惩罚的行为不会重复,直到想要鸽子去做的行为做成了。即便是在斯金纳的时代,这个简单的过程,一遍又一遍地重复,也可能会导致复杂的行为,计算机被设定成一次又一次地执行简单的操作,操作规模之大超出了人类的想象,计算系统可以通过这种方式学习非常复杂的技能。
强化学习(来源于网络)
例如,谷歌的 DeepMind 研究人员将深度学习和强化学习结合起来,教计算机玩雅达利(Atari)的电子游戏,计算机根本不知道这些游戏是怎么玩的,一开始,它的行为是随机的,它也仅仅得到屏幕在每个时刻的样子以及它的得分情况方面的信息,深度学习帮助它解释屏幕上的特征,强化学习则激励系统获得更高的分数,这台计算机很擅长玩其中的几个游戏,但它也完全玩不好其他的对人类而言易如反掌的游戏。
通过以类似的方式结合使用深度学习和强化学习,DeepMind 的 AlphaZero 程序取得了成功,先后在国际象棋和围棋比赛中击败人类棋手,尽管它只具备基本的游戏规则知识和一些谋划能力。AlphaZero 还有一个有趣的特点:它可以与自己进行数亿次的对弈,在此过程中,它会清除导致落败的错误,同时重复和阐明带来胜利的策略,这种系统,以及其他涉及到生成对抗网络技术的系统,会在生成数据的同时也在观察数据。
当你有计算能力将这些技术应用于非常庞大的数据集、数以百万计的电子邮件或 Instagram 图片或者语音记录时,你就得以解决以前看起来非常困难的问题,这就是计算机科学中令人兴奋的地方。
但是值得记住的是,这些问题——比如识别图片里的猫或者像“Siri”这样的口头词——对于一个蹒跚学步的人类来说是轻而易举的,计算机科学最有趣的发现之一是,对我们来说十分容易的问题(如识别猫)对计算机来说却很难——比下国际象棋或围棋困难得多。计算机需要数以百万计的例子来对对象进行分类,而我们只需用几个例子就可以对这些对象进行分类。
自上而下的贝叶斯模型
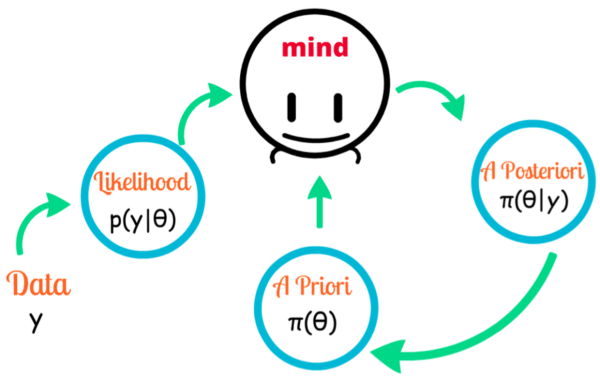
自上而下的方法在早期的人工智能发展中扮演了重要角色,在 2000 年,它也经历了一次复兴,以概率模型或贝叶斯生成模型的形式出现。
使用这种方法的早期尝试面临两种问题。首先,大多数的例证模式一般可以用许多不同的假设来解释:你来自期刊编辑的电子邮件可能是非垃圾邮件,只是看起来不太可能。其次,生成式模型所使用的概念从何而来?柏拉图和乔姆斯基说,你生来就有这些东西,但是我们如何解释我们是如何学习最新的科学概念的呢?小孩子又是如何理解恐龙和宇宙飞船的呢?
贝叶斯模型将生成式模型和假设检验与概率论相结合,旨在解决这两个问题。贝叶斯模型让你计算出在给定的数据下,某一特定假设成立的可能性,通过对我们已经拥有的模型进行小的系统性调整,并根据数据对其进行检验,我们有时可以从旧的概念和模型中创建新的概念和模型,但是这些优势被其他的问题所抵消,贝叶斯技术可以帮助你选择两个假设中哪个更有可能,但几乎总是有大量的潜在假设,没有一个系统可以有效地全盘考虑它们。
贝叶斯模型(来源于网络)
纽约大学的布伦登·莱克(Brenden Lake)和他的同事们用这种自上而下的方法解决了另一个对人类而言很简单,但对计算机非常困难的问题:识别不熟悉的手写字符。看看日本画卷上的一个字,即使你以前从未见过它,你也可以分辨出它是否与其他日本画卷上的字符相似或不同,你可能能够画出它来,甚至可以根据你看到的这个字符设计出一个虚假的日本字符。
用于识别手写字符的自上而下方法是,给计算机就每个字符提供数千个例子,并让计算机提取出显着的特征,而莱克团队则是给这个程序提供一个字符书写过程的通用模型:笔画要么向右,要么向左,完成一个笔画以后,开始写另一个,等等,当程序看到一个特定的字符时,它可以推断出最可能导致这个字符生成的笔画顺序——就像你基于垃圾邮件形成过程推断出你的邮件可能是垃圾邮件一样,然后它就可以判断一个新字符是来自于这个笔画顺序还是来自于另一个不同的笔画顺序,它自己也可以产生一组类似的笔画。
这个程序比应用于完全相同的数据的深度学习程序要有效得多,而且它切实反映了人类的行动过程。
这两种机器学习方法各有优缺点,在自下而上的方法中,程序一开始并不需要太多的知识,但是它需要大量的数据,并且只能以限定的方式进行归纳,在自上而下的方法中,程序可以从几个示例中学习,并做出更广泛、更多样的归纳,但是你需要在开始时为其灌输更多的东西,许多研究人员目前正试图将这两种方法结合起来,利用深度学习来实现贝叶斯推理。
人工智能最近的成功在一定程度上是源于那些旧思想的延伸,但更重要的是,多亏了互联网,我们有了更多的数据,多亏了摩尔定律,我们有了更多的计算能力来应用那些数据。
此外,一个未被重视的事实是,我们所拥有的数据已经被人类整理和处理过了,发布到网上的猫图是典型的猫的图片——人类已经选择的“好”图片,谷歌翻译之所以好用,是因为它利用了数以百万计的人工翻译,将其归纳应用到新的文本上,而不是真正理解句子本身。
儿童的学习方法与机器有何不同?
然而,关于儿童,真正值得注意的是,他们在某种程度上结合了每一种机器学习方法的最佳特征,并对它们完成巨大的超越。
在过去的 15 年里,发展主义者一直在探究孩子们从数据中学习结构的方式,四岁的孩子只需要像自上而下的系统那样从一两个数据例子中归纳出非常不同的概念,就可以学习,但是他们也可以从数据本身学习新的概念和模型,就像自下而上的系统一样。
例如,在实验室里,研究人员给孩子们一个“布利克特探测器”——一种他们从未见过的新机器,它是一个盒子,当你把特定的物体放在上面时,它就会发光并播放音乐,研究人员只给孩子们举了一两个例子来说明这个机器是如何运转的,告诉他们,放两个红色的方块在上面就可以让它运转,放一个绿色方块和一个黄色方块则不行。
即使是 18 个月大的婴儿也能立刻明白使得它运转的基本原理:两个方块必须是相同的。他们将这一原理推广到新的例子中:例如,他们会选择两个形状相同的物体来使得机器运转。在其他的实验中,研究人员已经证明,孩子们甚至可以弄明白,是某种隐藏的无形属性让机器得以运转,或者是机器是基于某种抽象的逻辑原理运转的。
你也可以在孩子们的日常学习中看出这一点。即使数据相对较少,幼儿也能像成人科学家那样迅速地学习抽象而直观的生物学、物理学和心理学理论。
近年来,无论是自下而上还是自上而下方法,人工智能系统在机器学习方面所取得的显着成就,都发生在一个由假设和概念构成的有限而明确的空间中——一组精确的游戏片段和动作,一组预先确定的图像。相比之下,儿童和科学家则有时会以激进的方式改变他们的概念,进行范式转变,而不是简单地调整他们已有的概念。
(来源于网络)
四岁的孩子能快速识别出猫和理解单词的意思,但他们也能做出创造性的、令人惊讶的新推断,这些推断也远远超出他们的经验范畴。例如,笔者自己的孙子最近解释说,如果一个成年人想再次成为一个孩子,他应该尝试不吃任何健康的蔬菜,因为健康的蔬菜可以让一个孩子成长为一个成年人,这种看似合理的假设是任何成年人都不会接受的,小孩子才会做出这样的假设。事实上,笔者和同事已经系统地证明,学龄前儿童比大一点的儿童和成年人更善于提出不太可能的假设,我们几乎不知道他们怎么会有这种创造性的学习和创新。
不过,看看孩子们都做些什么,可能会给程序员带来一些有用的关于计算机学习方向的提示,儿童学习的两个特点尤其引人注目,儿童是积极的学习者,它们不像人工智能那样被动地吸收数据。就像科学家做实验一样,孩子们的内在动机是,通过他们无休止的玩耍和探索,从他们周围的世界中获取信息。
最近的研究表明,这种探索比表面上看起来更有系统性,并且能够很好地找到有说服力的证据来支持假设的形成和理论选择,所以,如果将“好奇心”植入机器,并让它们与世界积极互动,可能是让它们的学习变得更真实、更广泛的一条路径。
其次,不同于现有的人工智能,儿童是社会和文化的学习者,人类不是在封闭的状态下学习,而是利用过去几代人所积累下来的智慧,最近的研究表明,甚至学龄前儿童也是通过模仿和聆听他人来学习的,但是他们并不只是被动地服从他们的老师,相反,他们以一种非常微妙和敏感的方式从他人那里获取信息,对信息的来源和可信度做出复杂的推断,并系统地将自己的经历与所听到的内容整合起来。
“人工智能”和“机器学习”听起来很可怕,在某些方面确实如此,例如,这些系统被用来控制武器,我们真的应该对此感到害怕。
然而,人的愚蠢比人工智能造成的破坏要大得多,我们需要变得比过去聪明得多,才能恰当地驾驭这些新技术,但对于人工智能取代人类,还有无论是世界末日预言还是乌托邦式愿景,都没有多少依据。
在我们解决学习的基本悖论之前,再好的人工智能也不如普通的四岁儿童。
第三十八届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:baiyl
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。