2013-11-07 10:23:31 来源:e-works
“性能”这个词可以说伴随着整个IT行业的发展,每次新的技术出现,从硬件到软件大多数情况下都围绕着性能提升而展开。“摩尔定理”指出CPU的处理速度每18个月会翻一番,但是进入21世纪的第二个十年来,似乎它的速度慢了下来。但是IT行业的各个行业领导者们,还是不断在计算机的性能寻求突破,继续挑战物理极限。细看存储行业,每款新的存储产品的推出,也围绕着如何更快、更好的服务前端服务器的I/O请求为中心。本文从I/O(Block)的流向介绍,试图解读整个I/O流与存储性能之间的些许联系。本文作为一篇存储基础的介绍文章,帮助读者了解看似简单的数据读写中的更多细节。
存储I/O流与存储性能:
存储I/O(后文简称I/O)的处理过程就是计算机在存储器上读取数据和写入数据的过程。这种存储器可以是非持久性存储(RAM),也可以是类似硬盘的持久性存储。一个完整的I/O可以理解为一个数据单元完成从发起端到接收端的双向的过程。在企业级的存储环境中,在这个过程会经过多个节点,而每个节点中都会使用不同的数据传输协议。一个完整的I/O在每个不同节点间的传输,可能会被拆分成多个I/O,然后从一个节点传输到另外一个节点,最后再经历相同的过程返回源端。
下图演示了一个文件在经过整个I/O路径中每个节点所进行的变化(以EMC Symmetrix存储阵列为例):
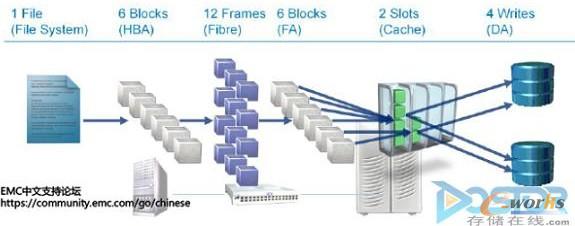
图1 文件在经过整个I/O路径中每个节点所进行的变化
整个I/O流经历一下几个节点:
File System – 文件系统会根据文件与Block的映射关系,通过File System Manager将文件划分为多个Block,请求发送给HBA。
HBA – HBA执行对这一系列的更小的工作单元进行操作,将这部分I/O转换为Fibre Channel协议,包装成不超过2KB的Frame传输到下一个连接节点FC Switch。
FC Switch – FC Switch会通过FC Fabric网络将这些Frame发送到存储系统的前端口(Front Adapter)。
Storage FA – 存储前端口会将这些FC 的Frame重新封装成和HBA初始发送I/O一致,然后FA会将数据传输到阵列缓存(Storage Array Cache)
Storage Array Cache – 阵列缓存处理I/O通常有两种情况:1.直接返回数据已经写入的讯号给HBA,这种叫作回写,也是大多数存储阵列处理的方式。2. 数据写入缓存然后再刷新到物理磁盘,叫做写透。I/O存放在缓存中以后,交由后端控制器(Disk Adapter)继续处理,完成后再返回数据已经写入的讯号给HBA。
Disk Adapter – 上述两种方式,最后都会将I/O最后写入到物理磁盘中。这个过程由后端Disk Adapter控制,根据后端物理磁盘的RAID级别的不同,一个I/O会变成两个或者多个实际的I/O。
根据上述的I/O流向的来看,一个完整的I/O传输,经过的会消耗时间的节点可以概括为以下几个:
CPU – RAM, 完成主机文件系统到HBA的操作。
HBA – FA,完成在光纤网络中的传输过程。
FA – Cache,存储前端卡将数据写入到缓存的时间。
DA – Drive,存储后端卡将数据从缓存写入到物理磁盘的时间。
下面的表中根据不同阶段的数据访问时间做了一个比较,一个8KB的I/O完成整个I/O流向的大概耗时。(表中的耗时根据每秒的传输数据整除获得,例如HBA到FA的速度有102,400KB/秒除以8KB得到78 μs)。根据表中的数据显而易见,I/O从主机的文件系统开始传输到存储阵列的缓存在整个这个I/O占比很小,由于机械硬盘的限制,最大的耗时还是在DA到物理磁盘的时间。如果使用闪存盘,那这个数据会大幅缩小,但是与其他几个节点的传输时间相比,占比还是比较大的。
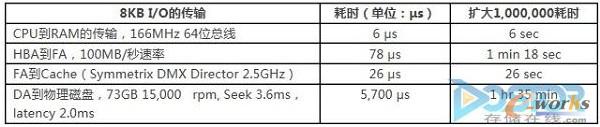
表1 不同阶段的数据访问时间比较
可以看到,存储阵列的缓存在整个I/O流中所起到的作用是至关重要。缓存的处理效率与大小,直接影响到I/O处理的速度。而然,在实际的环境中,即使存储阵列的缓存工作得当,主机的I/O也不会达到100 μs也就是0.1ms的水平,通常在1-3ms左右,就会认为I/O处理处于比较高性能的模式。原因就是因为另外两个因素“数据头处理”和“并发”。
1.“数据头处理“由于I/O流中每个I/O的数据组成并不是只包含数据,如下图所示,一个I/O除了数据以外还包含了Negotiation,Acknowledgement用来负责在I/O流中的每个节点传输和进行管理的。其中包含和TCP/IP一样的“Handshaking“信息以及流控制的信息,比如初始化传输,结束通讯等等。Header中则会定义一些例如CRC校验的信息,保证数据的一致性。所有这些数据的处理都会耗费一定的处理资源,增加I/O流的耗时。

图2 数据头处理
2.“并发“。由于I/O流整个过程中不可能只同时处理一个I/O,所有的I/O在HBA,FC,FA和DA处理的过程中都是已大量并发的情况下进行。而主要的耗时取决于I/O队列的等待,虽然存储阵列会在并发上进行优化。同一个处理Slice的处理还是会一队列形式进行。如下图所示,当存储同时面对多个I/O的处理的情况,总会有某个I/O会在整个流的最后出来,而增加I/O的耗时。所以说,在I/O流的每个节点出现瓶颈,或者短板的时候。I/O的耗时就会增加。
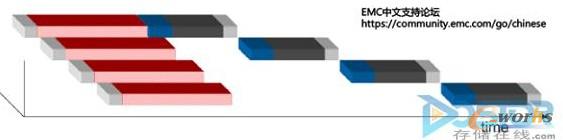
图3 存储同时面对多个I/O的处理的情况
综上所述,I/O流与存储性能的关系可以总结为以下几点:
完成一个I/O流主要经历过的节点有HBA,FC网络,存储前端口FA,存储缓存、存储后端口,物理磁盘。而很个过程中最耗时的是物理磁盘。
存储阵列的缓存的大小和处理方式直接影响到I/O流的性能,也是定义一个存储阵列优劣的重要指标之一。
I/O的处理速度通常会远离理论值,原因多个并发量较大而造成的队列延迟。
优化I/O的方式可以从多个节点入手,而最显着的效果是提升物理磁盘的速度。因为存储阵列会把尽可能多的数据放入缓存,而当缓存用满以后的数据交换则完全取决于物理磁盘的速度。
适当选用合适的RAID级别,因为不同的RAID级别的读写比例大不相同,可能使得物理磁盘处理耗时几倍增加。
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




