2013-08-12 09:55:41 来源:CSDN
大数据的重要性已毋庸置疑,但大数据的采集、存储、处理、分析、研究,却不是一朝一夕炼成的!数据平台如何建设,推荐系统如何运算等等,都是我们所关注的话题。
首先,迅雷基础研发中心数据平台技术总监陈仕明,主要从三个方面介绍了“迅雷数据平台建设及应用案例”。
中型数据平台
数据平台可以分成中型数据平台和大型数据平台,中型数据平台的主要特点是服务器资源、技术储备和人员都比较有限。迅雷的数据分析模块目前有500多台服务器,4000多个CPU,存储20P以上的数据,磁盘有3000多块,属于中型数据平台的规模。
迅雷的大数据架构
中型数据平台主要是基于开源已有的存储和计算,做一些更上层的外延性的产品。
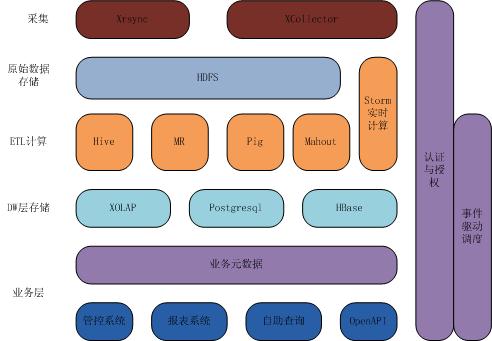
第一层是采集,采集分成实时采集和离线采用集,其中离线采集占了业务的大部分,主要用迅雷自己开发的Xrsync工具实现。有些数据需要涉及到实时计算,会同步发,存起来之后ETL计算全部用开源计算框架。实时采集主要是采集日志文件,这种日志文件主要对应业务服务器里边所生成的日志。
数据存储之后,依然是一个物理模型,为了降低维护成本,需要把技术人员的工作尽量抽出来,让其他岗位比如数据分析师做更多的事情。这就需要把底层数据抽象为业务人员理解的数据模型,抽完之后在最下边做了维护平台,以及报表系统,还有自主查询。
最右边有两块,一块是认证与授权,从上到下所有东西都需要经过认证和授权,作为一个公司级集中式的存储平台,每个部门存储都会在这儿做,所以你必须保障数据安全和资源合理分配。迅雷的平台认证,全部采用kerberos认证。数据存到HDFS上之后,会给每一个业务,或者每个产品,开辟一个kerberos帐号,所有帐号的数据都只能放在这个帐号的home里去,包括这个帐号的Hive或者HBase都存在该目录下,并控制存储空间。
另一块是事件驱动调度:首先,任务的依赖关系用数据打通。任务和任务之间的依赖关系其实质是任务背后的数据之间的依赖关系,某一个数据跑成功了之后依赖该数据的任务才能跑。
其次,需要把后置依赖前置改成前置驱动后置,前置任务跑成功了之后,将该任务对应的“数据事件”扔到调度总线里面去,由总线把需要依赖这个“数据事件”的其他任务调起来,当然该任务能够立即跑,还要考虑到底层计算引擎目前的负载等情况。
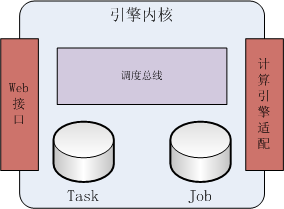
上图是调度引擎大体的架构:最核心部分是调度总线,数据分为是Task和Job,Task维护计算逻辑,如执行的SQL脚本等;Job维护调度逻辑,如依赖什么“数据事件”, 一个Task可以配置多个Job。最左边是Web接口,前端通过该接口查询任务状态,以及控制任务等。最右边是计算环境的适配层。
[page] 数据平台使用案例
迅雷会把收集来的数据做成数据模型,最重要的数据模型是一个用户事件模型,所有的基于用户端的这种行为数据,都可以把它抽象成模型存进去,这个模型用一句话概括就是,谁对谁的什么东西做了什么事情?
这个模型拥有很多纬度,如产品纬度,用户纬度,时间纬度,客户纬度、地域纬度,运营商纬度,终端纬度,渠道纬度,事件纬度等。
这个模型能做什么:简单的比如每个产品的上线用户数,每个用户的活跃度,用户的黏性,以及某个产品的用户的地域分布,运营商分布等,活跃用户排名,最热的资源排名,如哪些电影是最常看,发生某个事件所消耗时间是多少,或者某个商品的销售收入等。

图:迅雷基础研发中心数据平台技术总监陈仕明
迅雷还构建了一个用户的染色库,迅雷拥有几亿的用户,但是这些用户各有什么样的特征?比如是联通用户还是电信用户,还是某个小运营商的用户?还有兴趣类标签,如游戏类标签,影视类标签等。游戏标签描述该用户喜欢什么类型游戏,影视类标签描述用户喜欢什么类型的影视;根据这些属性我们可以更好的为用户服务。
另外一个是资源的属性库。比如一个影视文件,在资源属性库拥有该文件对应的电影的名称,演员,以及电影类型等。
染色库和资源属性库的应用主要有:比如,可以计算视频指纹,根据两个视频指纹相似度计算这两部电影是不是一部电影。染色库还会应用在会员tips推广中,迅雷会弹一些tips,为了提高tips的效果,提高点击率,需要尽量精准的投放。另外在看看里边放广告的时候,也需要尽量的精准,不能最好不要把一个女性的产品,给一个男屌丝推,这样一般点击率会很差。
接下来,腾讯数据中心数据挖掘研究员肖磊,从业务的角度为我们介绍了腾讯的大数据应用之一精准推荐。他的演讲主要包括四个部分:
[page] 腾讯做了什么
2012年的时候,腾讯赞助了KDDCup主要做了两个事情,一个是微博上面的推荐,一个是广告的推荐。具体到产品上面,包括腾讯视频的推荐系统,易迅首页上的推荐,基于社交网络广告的推荐广点通,还有朋友关系链的推荐等。这些推荐都是通过分析腾讯8亿的活跃用户做出的。

图:腾讯数据中心数据挖掘研究员肖磊
遇到的问题
肖磊认为作为一个推荐系统,首先要处理好3P之间的关系。
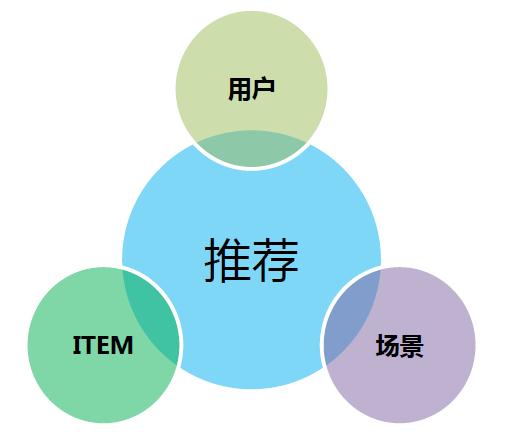
首先是用户,其次是ITEM,第三是场景,针对不同的场景不同位置有不同的方法做应用。
解决之道——3S
分别是数据、算法和系统。这三个是相辅相成的。
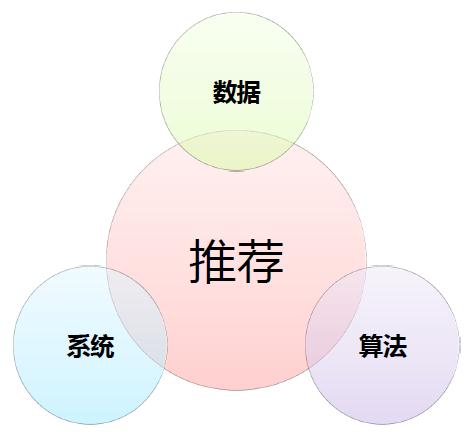
会基于用户的基本信息和历史数据构建用户画像的体系,上图中提到推荐的解决之道中,数据是排在第一位的,因为数据是做好准确推荐的立根之本。
两大核心平台
有两大核心平台做这件事情,一个平台是分布式数据仓库TDW,它基于开源的Hadoop和Hive进行了大量优化和改造。第二个是一套实时推荐的平台——APOLLO,它有一些实时介入系统、流式计算系统、一个分布式的存储系统,同时还有一个很重要的推荐引擎。
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




