MapReduce运行原理
MapReduce运行原理
2018-11-14 16:10:57 来源:搜狐 抢沙发
抢沙发
2018-11-14 16:10:57 来源:搜狐
摘要:MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。MapReduce采用”分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。
关键词:
MapReduce
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。MapReduce采用”分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是”任务的分解与结果的汇总”。
MapReduce架构
先来看一下MapReduce1.0的架构图
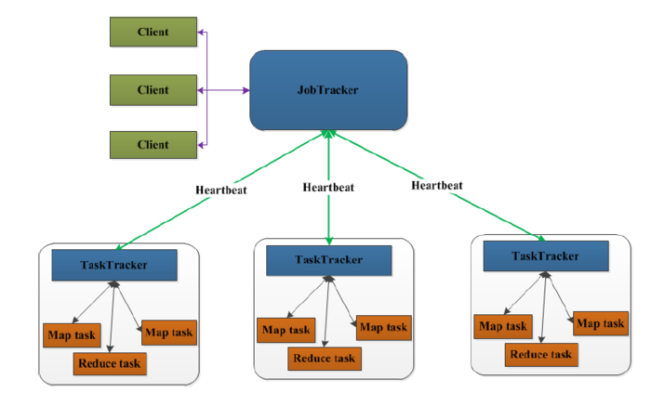
上图中的TaskTracker对应HDFS中的DataNode,
在MapReduce1.x中,用于执行MapReduce任务的机器角色有两个:一个是JobTracker;另一个是TaskTracker,JobTracker是用于调度工作的,TaskTracker是用于执行工作的。一个Hadoop集群中只有一台JobTracker。
流程分析
- 在客户端启动任务,客户端向JobTracker请求一个Job ID。
- 将运行任务所需要的程序文件复制到HDFS上,包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分信息。这些文件都存放在JobTracker专门为该任务创建的文件夹中。文件夹名Job ID。
- JobTracker接收到任务后,将其放在一个队列里,等待调度器对其进行调度,当作业调度器根据自己的调度算法调度到该任务时,会根据输入划分信息创建N个map任务,并将map任务分配给N个TaskTracker(DataNode)执行。
- map任务不是随随便便地分配给某个TaskTracker的,这里有个概念叫:数据本地化(Data-Local)。意思是:将map任务分配给含有该map处理的数据块的TaskTracker上,同时将程序JAR包复制到该TaskTracker上来运行,这叫“运算移动,数据不移动”。而分配reduce任务时并不考虑数据本地化。
- TaskTracker每隔一段时间会给JobTracker发送一个Heartbeat(心跳),告诉JobTracker它依然在运行,同时心跳中还携带着很多的信息,比如当前map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当JobClient查询状态时,它将得知任务已完成,便显示一条消息给用户。
以上是在客户端、JobTracker、TaskTracker的层次来分析MapReduce的工作原理的,下面我们再细致一点,从map任务和reduce任务的层次来分析分析吧。
MapReduce运行流程
以wordcount为例,运行的详细流程图如下
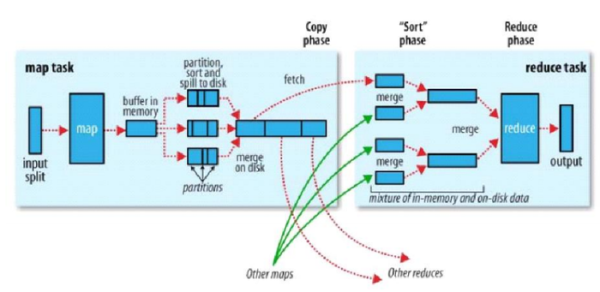
1.split阶段
首先mapreduce会根据要运行的大文件来进行split,每个输入分片(input split)针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据位置的数组。输入分片(input split)往往和HDFS的block(块)关系很密切,假如我们设定HDFS的块的大小是64MB,我们运行的大文件是64x10M,mapreduce会分为10个map任务,每个map任务都存在于它所要计算的block(块)的DataNode上。
2.map阶段
map阶段就是程序员编写的map函数了,因此map函数效率相对好控制,而且一般map操作都是本地化操作也就是在数据存储节点上进行。本例的map函数如下:
- publicclassWCMapperextendsMapperLongWritable,Text,Text,IntWritable{@Override
- protectedvoidmap(LongWritablekey,Textvalue,Contextcontext)throwsIOException,InterruptedException{
- Stringstr=value.toString();
- String[]strs=StringUtils.split(str,'');for(Strings:strs){
- context.write(newText(s),newIntWritable(1));
- }
- }
- }
根据空格切分单词,计数为1,生成key为单词,value为出现1次的map供后续计算。
3.shuffle阶段
shuffle阶段主要负责将map端生成的数据传递给reduce端,因此shuffle分为在map端的过程和在reduce端的执行过程。
先看map端:
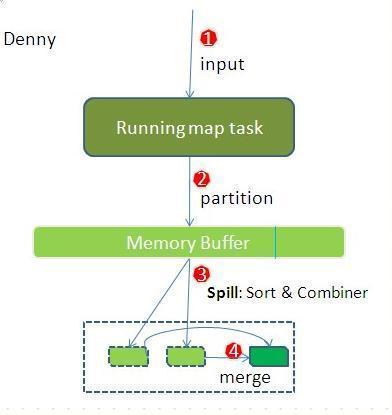
- map首先进行数据结果数据属于哪个partition的判断,其中一个partition对应一个reduce,一般通过key.hash()%reduce个数来实现。
- 把map数据写入到Memory Buffer(内存缓冲区),到达80%阀值,开启溢写进磁盘过程,同时进行key排序,如果有combiner步骤,则会对相同的key做归并处理,最终多个溢写文件合并为一个文件。
reduce端:
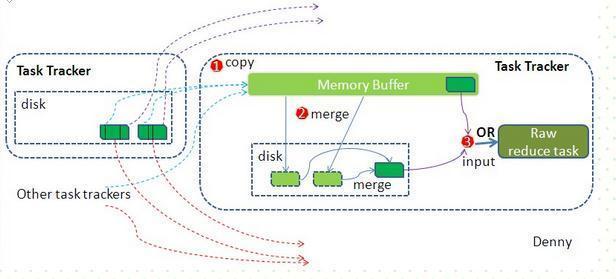
reduce节点从各个map节点拉取存在磁盘上的数据放到Memory Buffer(内存缓冲区),同理将各个map的数据进行合并并存到磁盘,最终磁盘的数据和缓冲区剩下的20%合并传给reduce阶段。
4.reduce阶段
reduce对shuffle阶段传来的数据进行最后的整理合并
- publicclassWCReducerextendsReducerText,IntWritable,Text,IntWritable{@Override
- protectedvoidreduce(Textkey,IterableIntWritablevalues,Contextcontext)throwsIOException,InterruptedException{intsum=0;for(IntWritablei:values){
- sum+=i.get();
- }
- context.write(key,newIntWritable(sum));
- }
- }
MapReduce的优缺点
优点:
- 易于编程;
- 良好的扩展性;
- 高容错性;
4.适合PB级别以上的大数据的分布式离线批处理。
缺点:
- 难以实时计算(MapReduce处理的是存储在本地磁盘上的离线数据)
- 不能流式计算(MapReduce设计处理的数据源是静态的)
- 难以DAG计算MapReduce这些并行计算大都是基于非循环的数据流模型,也就是说,一次计算过程中,不同计算节点之间保持高度并行,这样的数据流模型使得那些需要反复使用一个特定数据集的迭代算法无法高效地运行。
第三十八届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:pingxiaoli
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




