2012-09-27 11:18:49 来源:CIO时代网
Hypertable和HBase分别是BigTable的两个开源实现:HBase主要使用Java语言开发,而Hypertable使用Boost C++,另外在一些细节的设计理念上也有所不同。
Hypertable是一个开源、高性能、可伸缩的数据库,采用与Google的BigTable相似的模型。BigTable让用户可以通过一些主键来组织海量数据,并实现高效的查询。
Hypertable系统主要包括Hyperspace、Master和Range Server三大组件(如图1所示)。Hyperspace是一个锁服务,地位相当于Google的Chubby,主要用于同步、检测节点是否发生故障和存放顶层位置信息;Master主要用于完成任务分配,未来会有负载均衡以及灾后重建(Range Server失效后自动恢复服务)等其他作用;Range Server是Hypertable的实际工作者,主要负责对一个Range中的数据提供服务,此外它还肩负起灾后重建的责任,即重放本地日志恢复自身故障前状态;另外,还有访问Hypertable的客户端Client等组件。
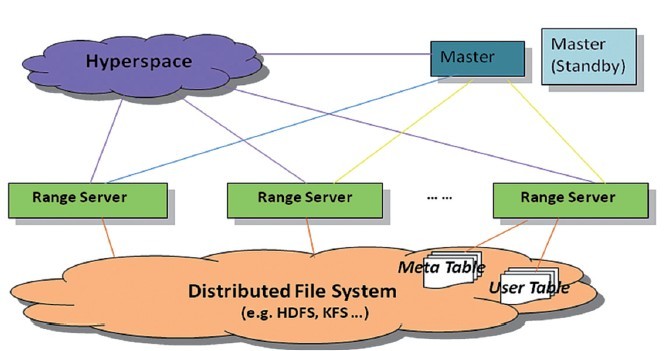
图1 Hypertable原有架构示意图
业务应用
Facebook在SIGMOD 2011会议上介绍了基于Hadoop/HBase的三种应用系统:Titan(Facebook Messages)、Puma(Facebook Insights)和ODS(Facebook Internal Metrics)。Titan主要用于用户数据存储,Puma用于MapReduce分布式计算,ODS用于存储公司内部监控数据,Facebook基于HBase的应用方式与国内几大互联网公司类似。
和ODS类似,对于一些硬件或软件的运行数据,我们会保存监控数据到数据库中,供软件工程师或者运维工程师查询。这里的查询可能是大批量的,也可能是个别条目;可能是延迟查询,也可能是即时查询。将此类业务的需求总结如下。
要求存储容量非常大,往往达到10~100TB,10亿~100亿条记录。
需要支持自动扩容,因为数据的增长模式不易估计,可能出现短时间的爆炸性增长。
写吞吐的压力较大,每秒超过1万次的插入。
近期导入数据能够快速检索。
需要支持扫描早期的大量数据,例如支持周期性的检查或回滚。
这里可选的一个方案是使用传统的DBMS(如MySQL)。但它存在如下弊端:首先MySQL单机存储有上限,一般超过1.5GB性能就会有波动;不过即使MySQL支持拆表,也并非完全分布式的,由于表的大小限制,对于不规则的数据增长模式,分布式MySQL也并不能很好地应对,如果抖动频率较大,需要引入较多的人工操作来进行数据迁移;再者MySQL也不支持表的Schema动态改变。另一个可选方式是使用Hadoop.不过MapReduce并非实时计算,并且HDFS不支持随机写,随机读性能也很差。
综上分析,我们选择BigTable类型的系统来支持业务需求,即使用Hypertable+Hadoop的方式(如图2所示)。
图2 监控数据收集与查询示意图
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




