Google的人工智能AlphaGo刚刚刚在围棋领域60连胜,百度也玩起了人机大战。
综艺节目《最强大脑》在第四季设置了人机对战环节,百度将“百度大脑”的人工智能技术植入到机器人“小度”人上,来节目上踢馆。
《最强大脑》中有个名人堂,里面全是以往节目中的高手,是心算、辨音、记忆等各个领域各自的大师。小度要和名人堂中的某位选手在人脸识别、语音识别上面PK。前三期人机大战,采用三局两胜制,百度大脑如果胜出,将参加最后的脑王争霸赛。百度深度学习研究院(IDL)主任林元庆表示,当时只拿了一台机器,而且不是在云端算。
最后选定跟百度大脑对战的选手是世界记忆大师王峰,他是本次名人堂的轮值主席。虽然是记忆大师,不过据他自己和现场的科学评审清华大学教授魏坤琳(人称“Dr.魏”或者“叨叨魏”)说,其实人脸识别不是他最强的,记忆才是。不过现场一开始发生了无人敢于对AI应战的局面,推让鼓励一番后,最后评审们还是选了王峰应战。
比赛分为两轮,在第一轮,嘉宾(章子怡)从女子团体蜜蜂少女队20名成员的童年照中挑出2张,然后蜜蜂少女队会在现场跳舞,选手通过动态视频表演观察少女模样,从中选出童年照的主角。
在第二轮,节目组请来30名30岁以上的观众,嘉宾(中国乒乓球队主教练刘国梁)挑出一位,随后选手要将其从30张小学集体照中找出谁是他。
其实王峰也非常腻害地匹配三张照片中的两张,只是在第一轮的第二张里面,没想到蜜蜂少女队里面有一队双胞胎,好像她们俩也不太记得照片中的是姐姐还是妹妹[捂脸],王峰就输了这局。其实在这里,小度也给出了两个答案,一个匹配度为72.98%,另一个72.99%,最后吴恩达现场选了72.99%的照片,匹配正确。
可以说,王峰虽然自称不擅长人脸识别,但表现非常出色,面对这样的对手,小度可以说只是险胜。林元庆也曾表示,这个过程很忐忑,也很兴奋。忐忑的是害怕“事情能搞定吗?”兴奋的是,“终于有一个机会去看一看我们的人工智能技术做了这么多年,跟人还有多大的差距,或者是已经到达了什么样的水平”。
林元庆表示,在被江苏卫视选中为参加节目的公司之后,百度仅能得知比赛形式,比如第一期的跨年龄人脸识别;在后面的两个月的备战中,百度IDL团队通过了大量的数据去训练百度大脑,图片大部分来自互联网,也有一部分是百度买的图片,因为跨年龄照片比较难获取。数据量级大概是两百万人,每个人有一百张照片。
人工智能进行人脸识别的流程
当嘉宾问到现场选手王峰是怎么做到的,王峰说会先记住目标人物脸上一些不会随着年龄而改变的特征,比如鼻子、耳朵、嘴角。那么人工智能又是如何做人脸识别的呢?
其实跟王峰用的方法也很类似,通过提取特征去匹配,但以前,可能是人类挑出具体的特征,现在运用深度学习的方式,机器可以自己去学习什么样的特征是有用的。
百度目前用的也是深度学习的方法,林元庆介绍:“我们会把人脸分成七个部位,在这七个部位上学习哪些特征是非常重要的,不是人来挑选的,是人自动学习的,我们会收集这些数据,收集完之后告诉机器这个人小时候长这样,这个人大了长这样,让机器自己去学,哪一些特征是非常重要的特征。”
不过,林元庆也发现,参加了《最强大脑》之后,他们发现,非共性的特征,也许可以是机器学习的进步方向。比如说一个人嘴边长了一颗痔,机器学习就比较难,因为不是共性,只是一个案例里面发生的。“从数据的角度来讲,也是一个强板,也是一个短板,很多学习出来的特征是共性的特征。但是那些比较独特的特征,或者比较个性化的一些特征地我们是没有很好的利用。”
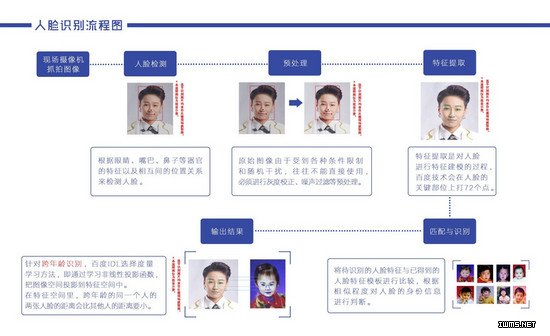
据百度方面介绍,通常情况下,人脸识别的流程如下图:
以比赛为例,现场小度识别蜜蜂少女成员的原理流程图
百度介绍,具体可以分解成以下几个步骤:
1、人脸检测
根据眼睛、眉毛、嘴巴、鼻子等器官的特征以及相互之间的几何位置关系来检测人脸,即在在一副图像或一序列图像(比如视频)中判断是否有人脸,若有则返回人脸的大小、位置等信息。
图片来源于参考文献:《人脸识别——原理、方法与技术》,王映辉编,科学出版社
2、人脸图像预处理
系统获取的原始图像由于受到各种条件的限制和随机干扰,往往不能直接使用,必须在图像处理的早期阶段对它进行灰度校正、噪声过滤等图像预处理。人脸图像的预处理主要包括: 人脸对准, 人脸图像增强,以及 归一化等工作。
人脸对准是为了得到人脸位置端正的人脸图像。
图像增强是为了改善人脸图像的质量,不仅在视觉上更加清晰图像,而且使图像更利于计算机的处理与识别。
归一化工作的目标是取得尺寸一致,灰度取值范围相同的标准化人脸图像。
3、人脸图像特征提取
人脸特征提取就是针对人脸的某些特征进行的。人脸特征提取,也称人脸表征,它是对人脸进行特征建模的过程。
图片来源:百度方面提供
4、人脸图像匹配与识别
人脸识别就是将待识别的人脸特征与已得到的人脸特征模板进行比较,根据相似程度对人脸的身份信息进行判断。这一过程又分为两类:
一类是人脸确认,是一对一进行图像比较的过程,将某人面像与指定人员面像进行一对一的比对,根据其相似程度来判断二者是否是同一人,相似程度一般以能否超过某一量化阀值为依据。
另一类是人脸辨认,是一对多进行图像匹配对比的过程,将某人面像与数据库中的多人的人脸进行比对,并根据比对结果来鉴定此人身份,或找到其中最相似的人脸,并按相似程度的大小输出检索结果。据林元庆介绍,在百度的大厦里已经落地的闸机、今年乌镇互联网大会中的刷脸注册系统,人停留1到2秒即可通过,这就是1比N的人脸识别。
节目中人脸识别的难点
在上述人脸识别的过程中,机器可能会遇到什么难点?节目中女子团体唱唱跳跳,脸部不断,而且灯光闪烁的,会不会增加人脸识别的难度?那技术上可以怎么解决?
Dr.魏表示,光照条件差、视角独特、信息模糊,甚至变形,这些特殊情况都会给机器很大的挑战。声音识别的挑战也是一样,机器需要从极少的线索中提取出稳定不变的信息,并作出推演,不是简单的信息匹配和分类问题,而是从模糊复杂的信息中抽象出规律的问题。节目组把上述的要素都设计到了舞台上的挑战当中。
对于人脸的摇晃,百度方面的技术负责人表示,在比赛的过程中,少女团体的表演是动态,机器会自动的找姿态比较端正的来识别。
不过,除了表情、角度观察、光照条件之外,人脸遮盖物,如口罩、墨镜、帽子、头发、胡须,甚至是整容、P图等行为,都会增加了人脸识别的难度。
现场的女子团体都是化妆上台表演、不排除有带美瞳和微整形的情况,而且还出现双胞胎的情况。百度方面解释,人脸识别是在脸部骨骼上取尽可能多的点,通过计算机把这些点分别与自己已经存储的脸比较,双胞胎之所以难以识别,就是骨骼太相似,需要取足够多的点。
林元庆说,节目中的任务之一:跨年龄识别,也是目前的难点。
他解释,一般而言,在跨年龄阶段人脸识别中,类内变化通常会大于类间变化,这造成了人脸识别的巨大困难。同时,跨年龄的训练数据难以收集。没有足够多的数据,基于深度学习的神经网络很难学习到跨年龄的类内和类间变化。
基于第一点,百度IDL的人脸团队采用的事度量学习的方法。即通过学习一个非线性投影函数,把图像空间投影到特征空间中。在这个特征空间里,跨年龄的同一个人的两张人脸的距离会比不同人的相似年龄的两张人脸的距离要小。
针对第二点,考虑到跨年龄人脸的稀缺性。百度用一个用大规模人脸数据训练好的模型作为底座,然后用跨年龄数据对其做更新。这样不容易过拟合。
将这两点结合起来做端到端的训练,可以大幅度提升跨年龄识别的识别率。
图像识别比下围棋更low?
AlphaGo连胜人类60局之后,百度大脑险胜《最强大脑》,不免有很多人拿两者来比较,甚至有媒体认为围棋比图像识别难多了,究竟哪个比较腻害?
当被问到这个问题的时候,Dr.魏认为,两者很难比较。百度大脑在舞台上比的是视听觉能力,但AlphaGo比的是所谓的运算能力、所谓的逻辑推理能力。
他解释,人下棋,除了逻辑推理和运算能力的积累,还依赖所谓的棋感,就是棋艺上面的所谓的直觉。这是不能直接用语言描述的,不过脑科学是有研究的,直觉也是大数据跑出来的,即平时大量的练习养成的。从这方面来说,AI也是一样的,深度学习基于大量的数据,形成的下棋模型是设计者也不能准确描述的一套算法。
他还表示,人认为最简单的事情,对人工智能来说是很困难的。
人类擅长感知和运动,恰恰不擅长逻辑和运算为代表的抽象思维能力。机器却似乎恰恰相反,不擅长感知和运动,机器人能下围棋或者记下海量的信息,但是没有办法像人这样运动,或者像人一样去感知这个复杂而快速变化的世界。
他举例,人类可能在三岁的时候就会爬楼梯,但是现在我们都不知道怎么让机器人像人一样流畅地爬楼梯,特别是楼梯的好多参数是无法预知的时候。人可以爬各种各样的楼梯,在不同光照条件,不同身体状况等,但是机器人到现在无法象人一样流畅。从进化上来说, 运动,包括像爬楼梯这样的运动,大脑很早就学会了,而人学会围棋对进化中的大脑来说,是很晚才开始玩的。所以,对人来说,楼梯容易一点,围棋难一点;但是可能对机器来说围棋更容易一些,上楼梯更难一些。
其实运动、感知,还有其他认知活动,像下围棋、搞记忆,都是大脑的功能。人工智能对不同认知功能有它的难易评判,我们不能用人的直觉去做这个评判。我相信我回答你的问题了,所以这两个就像苹果和橘子,不能比。
图像识别目前的应用
虽然百度的图像识别技术目前已有较高的准确率,但是在哪些方面有应用呢?
具体人脸识别方面,林元庆表示,其实人脸识别在百度内部,最大是搜索,百度基本上对全网的照片都做了人脸识别。“你搜Dr.魏,会出来一串的Dr.魏的照片。”
魏坤琳
至于人脸识别在其他领域的应用,大概是三个大方向:
第一个是智能景区的人脸识别闸机。
第二个方面是金融领域,比如说百度金融的远程预授信。
第三个方面,百度还在和一些手机厂商谈,内嵌百度的人脸识别技术。
至于大的图像识别方面,实验室还在开发的一个方向是做医疗图象分析,比如X光或者CT的照片,将细胞都给它分割出来,判断每一个细胞是不是癌细胞。
在百度深度学习实验室内部,林元庆介绍,目前计算机视觉做的方向大致有三个,除了人脸识别,还有智能驾驶和增强现实。智能驾驶是2015年从深度学习实验室孵化出去的项目,专门成立了独立的事业部做智能驾驶。2016年,增强现实也独立出去,成立了增强现实实验室,这两个是深度学习实验室孵化出来的项目。
他表示,百度之前主要做技术的积累,2017年希望在市场上大规模应用。
第三十八届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:pingxiaoli
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。