北京时间9月13日凌晨,苹果在新的总部召开发布会,发布新的智能手表、电视和手机等一系列新产品。这是最受科技界关注的发布会之一。
今年的苹果新品发布会首次在苹果新总部的史蒂夫?乔布斯剧院举行,苹果CEO蒂姆?库克在发布会的介绍中,重申了乔布斯精神。本次发布会最受关注的便是苹果的新手机,传说中的iPhone8,令人惊喜的是,苹果本次发布会带来了最最重量级的智能手机——iPhone X (苹果10)。增加了人脸识别解锁Face ID的这款新手机,应该是迄今为止这家最受关注的智能手机生产商推出的最AI的一部手机了。
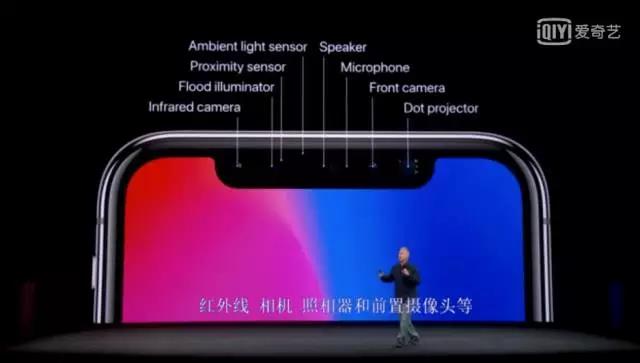
首先,这是一部全屏幕的、没有Home键的iPhone,支持无线充电。
iPhone X 最值得关注的一点便是通过人脸识别进行解锁,这在苹果发布会之前就已经传得沸沸扬扬的功能终于得到了确认。
苹果人脸识别解锁9大特征
根据苹果在发布会现场的介绍,苹果的人脸识别解锁Face ID包含了9大特点:
人脸验证 (Face authentication)
TrueDepth 摄像头
验证简便
专门的神经网络
自然和安全
用户隐私
注意力察觉
自适应性
Apple Pay和其他应用的绑定
根据官网的介绍,Face ID 功能通过原深感摄像头来实现,设置起来也非常简单。它会投射超过 30,000 个肉眼不可见的光点,并对它们进行分析,为你的脸部绘制精确细致的深度图。
详细来看,在安全上,苹果自称,他们人脸识别的错误率是百万分之一。另外,数据的处理都是在设备上进行的,解锁是会通过识别用户的注意力来进行判断。
具体可以再看一下另一大特点:TrueDepth 摄像头
技术核心:苹果 A11 和 A11 Bionic 芯片
据介绍,iPhone X 将采用定制的芯片来处理人工智能工作负载。这是一个双核的“A11生物神经网络引擎”(A11 bionic neural engine)芯片,每秒运算次数最高可达6000亿次。
该芯片赋能的最重要的事情就是使 Face ID 身份认证功能能够快速识别人脸,从而解锁 iPhone X 或进行购物。
这个消息并不出乎意外。早在今年5月,彭博就曾经报道,苹果公司正在为iPhone开发AI芯片,但不清楚该芯片是否已经准备好可以用在今年最新的iPhone产品上。
而且,芯片走向定制化,以满足AI软件的需求,在行业中已经变成一股新的大趋势。 Alphabet的谷歌已经设计了两代芯片来处理数据中心的AI计算工作负载。 微软也为未来版本的HoloLens混合现实头盔开发了一款AI芯片。
在iPhone上安装新的专用芯片意味着主芯片的工作量将会减少,从而提高电池寿命。 否则,例如,通过手机摄像头进行物体识别同时进行视频录制时,可能会迅速地将电池消耗完。
此外,在不久的将来, iPhone以外的更多移动设备都可能包含针对AI的处理器。
Burke 在今年的谷歌 I/O 会议上曾说:“随着时间推移,我们预计会看到专门为神经网络的推理和训练设计的DSP(digital signal processors,数字信号处理器)的出现。”
虽然今天的消息肯定会占满新闻头条,但苹果其实以前就已将AI用途的芯片置于iPhone中。iPhone 7就包含有一个FPGA,这是英特尔和微软为加速AI任务进行探索的。据福布斯报道,在iPhone7之前苹果没有在iPhone中使用过FPGA。
苹果对于芯片开发并不陌生。苹果已经在它的 iOS 设备上对其A系列处理器给予重视,并且在智能手机上专门使用了某些计算类型的组件。
本次发布会上对此前苹果一直重视和宣传的 Siri 着墨甚少,并且在最新的iPhone上,还特别强调,没有了Home键以后,可以通过手机侧面的按钮唤醒Siri。此前,Siri的一个宣传点难道不是直接语音唤醒,不需触碰控制吗?
最后看一眼价格:999美元,起。
苹果第一篇公开的人工智能论文:关于人脸识别,CVPR 2017最佳论文
苹果在7月20日推出名为 Apple Machine Learning Journal 的新研究博客,对苹果来说,做一个专门介绍他们的人工智能研究论文的博客还是挺新鲜的,因为苹果通常不会公开谈论他们的研究项目。
该博客发表的第一篇文章是关于如何将合成的图像变得更逼真,以用于训练神经网络。这也是苹果于去年年底在arXiv发布的第一篇AI论文“Learning from Simulated and Unsupervised Images through Adversarial Training”的介绍,这篇论文在 CVPR 2017 获得 best paper。
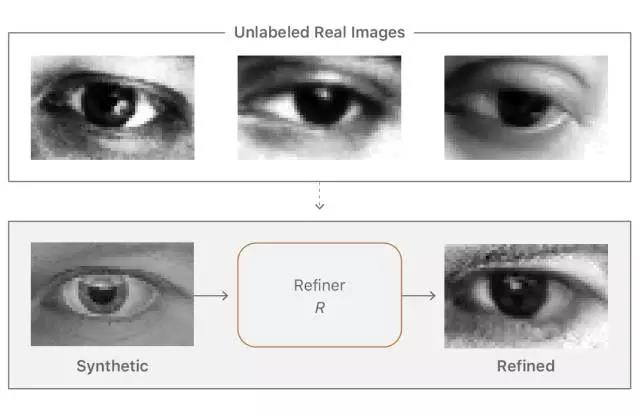
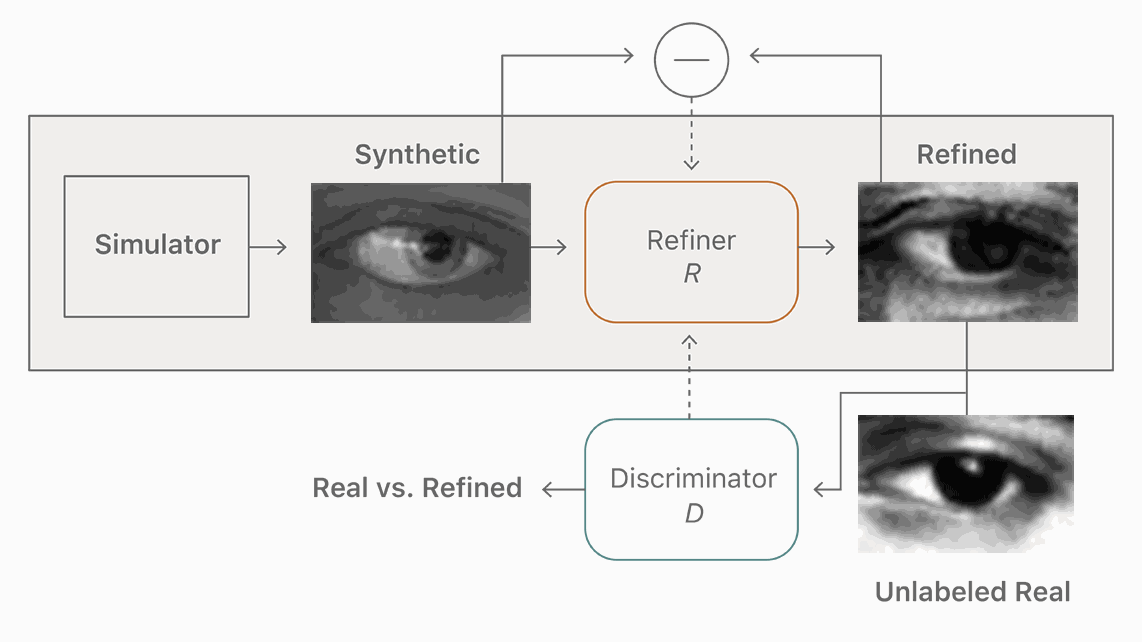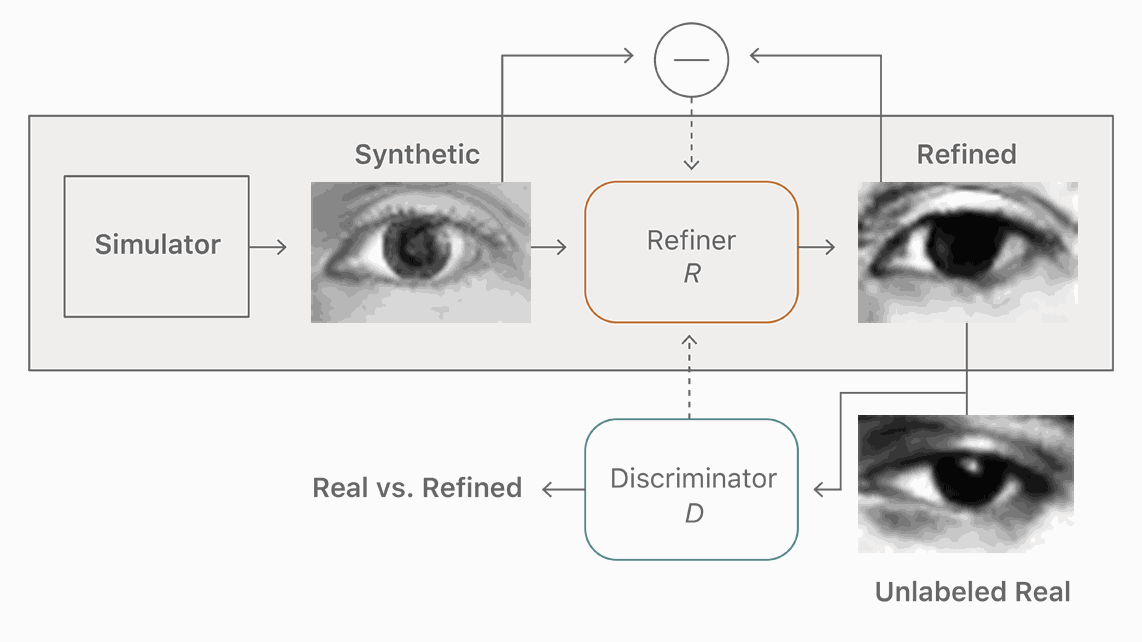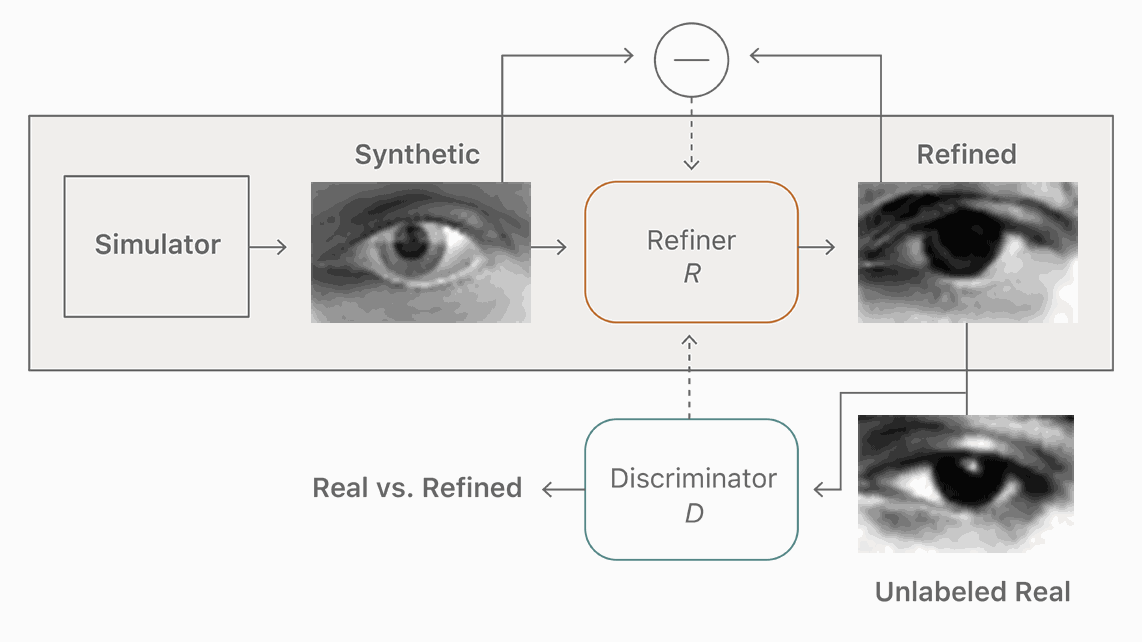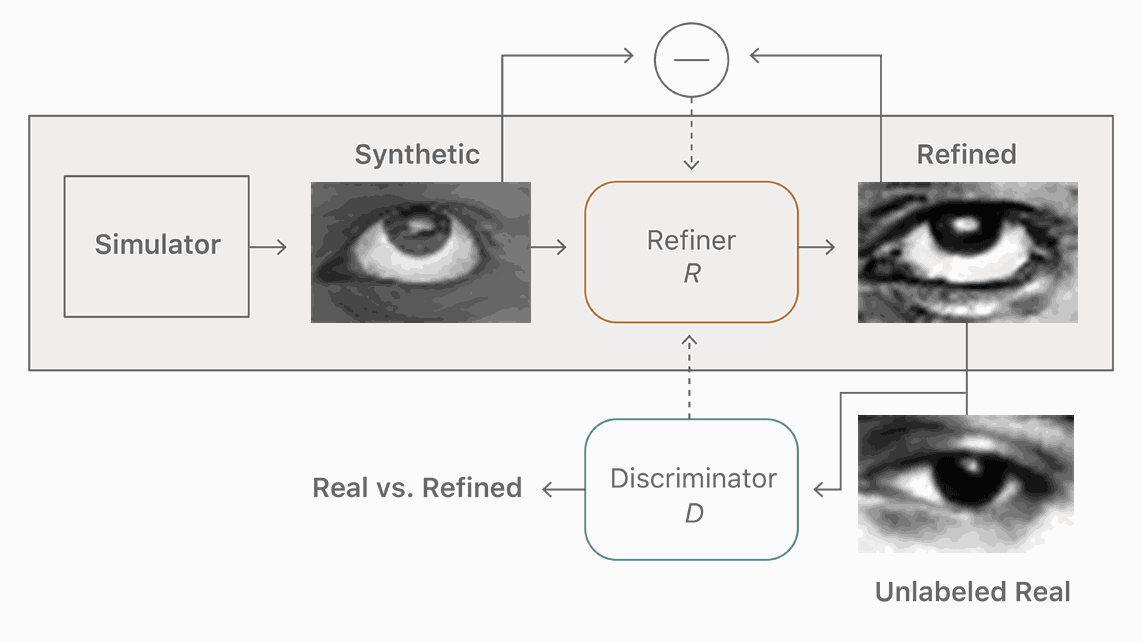
根据这篇文章,苹果要训练神经网络来检测照片上的人脸和其他物体。但苹果的方法不是制造拥有数百万计图像样本的巨大的数据集来训练神经网络,而是创建由计算机生成的人物的合成图像,并应用一个过滤器使这些合成图像更逼真。这比一般的方法训练神经网络的成本更低,而且速度更快。
在机器学习研究中,使用计算机生成的图像(例如电子游戏中的)训练神经网络比使用现实世界的图像更高效。因为生成的图像数据都是有标签和注释的,而真实图片的数据需要耗费人力标注计算机所看的东西,告诉它这是一棵树,一只狗,一辆自行车等等。但是生成图片的方法也有问题,因为这让算法所学到的东西并不总是能无缝转移到真实场景。生成图片的数据“常常不那么真实,导致神经网络只学习生成图片的细节,却无法在真实图片上很好地迁移。”苹果的论文如是说。
论文中用于举例的“未标注的真实图像”、“合成的图像”、“精细化的图像”等都是人的眼睛图片,或许,iPhone X 的 Face ID 新功能正是有利用这一方法,以及更多苹果没有公开的研究成果?
图:模型使用未标注的真实数据,利用模拟器改善合成的图像的真实性,同时保留注释信息。
地址:https://arxiv.org/abs/1612.07828
更聪明的Siri
苹果机器学习博客接着在8月连着发表3篇来自 Siri 团队的技术文章,分别是:
通过跨带宽和跨语言初始化改进神经网络声学模型(Improving Neural Network Acoustic Models by Cross-bandwidth and Cross-lingual Initialization)
反文本归一化作为标签问题(Inverse Text Normalization as a Labeling Problem)
Siri声音的深度学习:为混合单元选择合成的设备上深度混合密度模型(Deep Learning for Siri’s Voice: On-device Deep Mixture Density Networks for Hybrid Unit Selection Synthesis)
三篇文章题目看起来都非常高深,介绍了 Siri 背后的技术进步。其中第一篇文章讨论利用声学模型数据的迁移学习技术,以显着提升新的语言版本Siri的精确度,让Siri支持更多语言;第二篇介绍Siri如何利用机器学习格式化地显示日期、时间、地点等。第三篇则更综合地介绍Siri声音的进化,探讨如何利用深度学习让Siri更会说话。
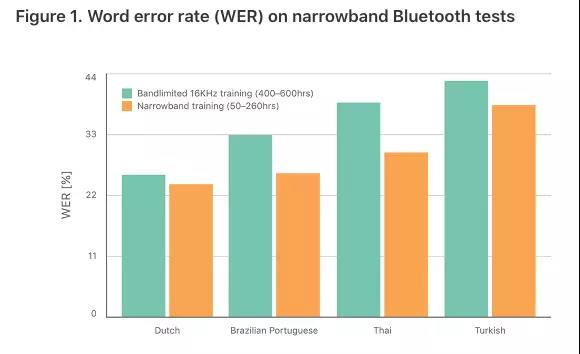
具体来说,Siri在2014年中推出一个新的语音识别引擎,使用深度神经网络(DNN)。先是用于美国英语,到2015年中扩展到13种语言。为了顺利扩展到其他语言,苹果研究人员需要使用有限的转录数据(transcribed data)来解决构建高质量的声学模型的问题。他们提出使用带限(band-limit)相对更多、更易于收集的宽带音频来解决较少量的窄带蓝牙音频问题。他们在迁移学习框架之上使用了神经网络初始化。
图:在窄带蓝牙测试上的词错率
图:跨语言初始化
另一值得一提的是Siri的文本转语音(TTS)系统:
从 iOS 9 到 iOS 11,Siri的声音对比
文章地址:https://machinelearning.apple.com/
第三十八届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:pingxiaoli
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。