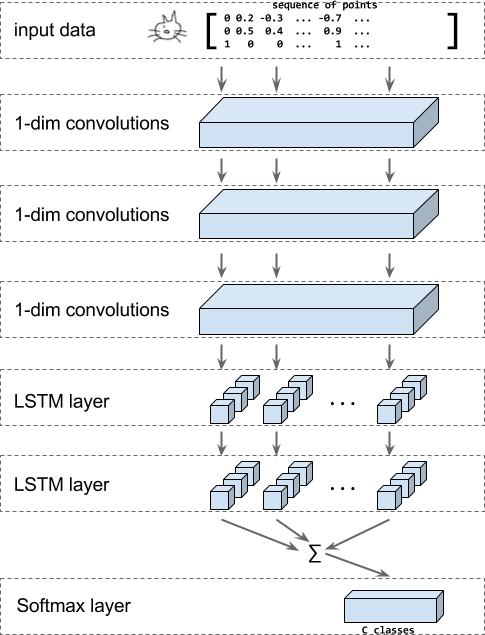
Quickdraw的CNN-RNN模型
"猜画小歌"用到的quickdraw模型本质上是一个分类模型,输入是笔画的点的坐标信息和每笔起始的标识信息,应用几个级联的一维卷积,再使用 BiLSTM 层并对结果进行求和,最后使用Softmax层进行分类。
整个网络结构如图:
模型结构
开源数据和代码详见后面参考文档。整个网络比较简单,而且用其默认的参数最终的模型准确率在75%,如下图,不算是一个要求较高的场景,效果已经足够好。
这里分享笔者注意到的有几个有意思的小细节(高手轻拍)。
小细节
数据预处理
对于stroke-3(x,y,n),Google默认使用的TFRecord数据对坐标做了归一化与差值处理。
# 1. Size normalization.
lower = np.min(np_ink[:, 0:2], axis=0)
upper = np.max(np_ink[:, 0:2], axis=0)
scale = upper - lower scale[scale == 0] = 1
np_ink[:, 0:2] = (np_ink[:, 0:2] - lower) / scale
# 2. Compute deltas. np_ink[1:, 0:2] -=
np_ink[0:-1, 0:2]
np_ink = np_ink[1:, :]
为什么归一化?
类似于输入层BN的作用,将数据的分布由原来激活函数的收敛区调整到梯度较大的区域
只关心画的笔画走势,而不关心画的大小,也就是说画一个大圆和画一个小圆在输入数据层面没有太大区别
为什么差值处理?
忽略起始坐标位置的影响,也就是说在画布的中间和四个角落开始作画同一个形状,在输入数据层面没有太大区别
卷积层
使用多个一维卷积(conv1d)级联,并使用线性激活函数,没有使用pooling层。
线性激活改为relu,准确率降了点,为73%
线性激活改为relu+加上pooling层(size=4,strides=4),准确率又降了点,为70%
为什么线性激活和去掉pooling层效果提升2-3个点?
pooling层有哪些作用:
降低参数量,事实上增加了pooling层使得训练时间缩短了一大半;
保持特征局部不变性,貌似我们的输入不是复杂的图片像素信息,而是笔画信息,而且做了差值处理,也不太需要局部不变性;
减少冗余,去除噪声,对于简笔画来说,可能作用也不是特别明显。
笔者(单纯的)理解简笔画已经是人类对于物体的高度抽象了,因此没有必要在用复杂的CNN网络去抽象特征,并且全局的特征有后面的RNN层获取。
小思考
Google 16年11月就推出了QuickDraw网页版,最近只是借助小程序又火了一把,之前已经获取过大量真实的用户数据,并用于这次小程序效果的优化。
模型还能用来做啥?
最近看到了一片研究这份简笔画数据中不同国家的人的绘画顺序与其国家文字的关系的文章,而且时序分类模型在异常分析、手写体识别、语音识别、文本分类等领域有大量的研究和进展。
画圆的不同
笔者研究生阶段曾经研究过电脑使用者的异常分析,根据用户的鼠标轨迹和键盘操作等特征建立分类模型识别是不是本人在操作。现在想来,直接拿这个模型来跑之前的任务,应该还不错。
产品层面,我们还能有些什么创新?
AutoDraw:能将你的涂鸦自动升华为美丽的艺术图像(Google已推出)
绘画故事:画4格漫画,系统自动生成一个故事(这个配合上层的NLG技术应该问题不大)
绘画打分:为你的绘画的创新性、技术性、完整性等自动评分
这些绘画数据还有什么可以挖掘的价值?
绘画是人在用自己的方式描述自己理解的世界,如果从这些简单的简笔画入手,能够从中学习出人理解物体和世界的方法,简单来说可以迁移到目前图像识别算法的高层抽象阶段,提升某些任务的效果;复杂一点甚至可以用作提升机器的推理能力,学习人类对物体和世界抽象建模的能力(脑洞)。
第三十八届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:pingxiaoli
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。