2013-10-28 11:02:50 来源:e-works
云计算在大数据处理方面,尤其针对几百MB、几百GB、甚至几百TB大小的文件,有了很好的应用,目前已经有存储PB级数据的Hadoop集群了。Google关于GFS、MapReduce、BigTable的三篇论文是云计算领域的经典。Apache 按照这三篇论文,用Java实现了开源的云计算Hadoop系统,性能上Hadoop不比Google优良,却也不影响Hadoop被业界广泛接受。
1.Hadoop系统介绍
Hadoop 由两个核心构件组成,Hadoop 分布式文件系统HDFS(Hadoop Distributed File System)和map/reduce计算模型。
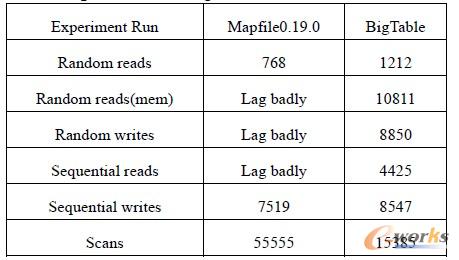
表1 Apache 与Google 云计算产品性能比较
HDFS 保留了传统文件系统特征的同时,也有海量数据存储、高性价比、可靠性、可扩展性等云计算领域的特征。HDFS 集群是由一个名字节点(NameNode)和多个数据节点(DataNode)构成。一个大数据文件被分成多个块,这些块存储在DataNode 中,由NameNode 确定每个块与DataNode的映射,并且命令DataNode进行文件或目录操作,如open、read、write、close 等。NameNode 的容错很重要,NameNode停机会造成HDFS 数据的丢失,安全起见Hadoop 会有NameNode 的备份,一旦NameNode 停机或异常,SecondaryNameNode 便会接管NameNode的工作,用户却不容易觉察到明显的中断。map/reduce 计算模型由一个调度协调任务的JobTracker 和多个执行来自JobTracker 指令的TaskTracker 组成。 map/reduce 程序提交给JobTracker 后,JobTracker获取当前网络拓扑中最优的数个节点,将map和reduce 任务交付给所选节点的TaskTracker。任务执行过程中,通过心跳机制,TaskTracker 向JobTracker 报告任务进度,通过更改heartbeat.recheck.interval 属性可以设置心跳的时间。当TaskTracker 不能完成任务或任务失败的时候,JobTracker 会选取效率高的TaskTracker 的结果,或者将任务重新下发给其他节点的TaskTracker。
图1,map/reduce 计算模型提供了任务的分解(map)和规约(reduce)来进行分布式计算。map函数对文件的每一行进行处理,产生(Key/Value)对。reduce以map的输出为输入,将相同的Key值规约至同一reduce,reduce 进一步处理后,产生新的数据集。形式化过程如下:
map: (k1,v1)→(k2,v2)→(k2,list(v2))
reduce: (k2,list(v2))→(k3,v3)
map将(k1,v1)经过处理,产生数据集(k2,v2), 归纳为(k2,list(v2));将(k2,list(v2))交予reduce处理,(k2,list(v2))成为reduce函数的输入,产生map/reduce计算的结果(k3,v3)。
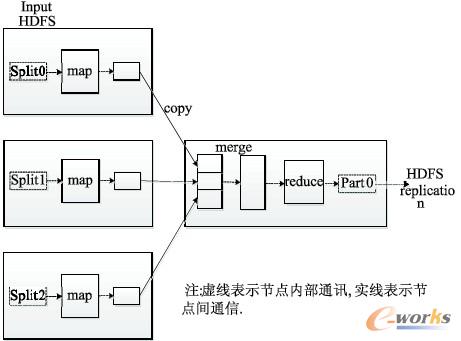
图1 map/reduce 计算模型
2.云计算技术
数据存储和分析效率,是判断服务优劣程度的重要指标。多年来,IT 界内存容量和磁盘容量大幅增加,然而数据存储和数据分析的效率却未能满足企业的要求。将云计算产品Hadoop 应用于数据的存储、分析,能提高数据存储和分析的效率。传统的数据存储、分析,将一张表存储在一台机器上,一条SELECT 语句被一台机器执行,影响效率的关键因素是单机的性能。HDFS 将一个大文件分块存储在集群的各个节点上,完成数据存储的分解;map/reduce 将一个数据分析任务下发到各个节点上,完成任务的分解。各个节点并行的进行数据存储和分析,最终通过归约各个节点的结果完成任务。Hadoop 系统强大的数据处理能力,鲜明的云计算的特征,已经被业界广泛的接受,并被应用于生产。
2.1 HDFS 的数据存储
数据文件有效记录 1221215 条,大小为457MB,每一行是数据库的一条记录,将数据备份至HDFS文件系统。图2从Web端展示了HDFS文件系统,它类似于Unix文件系统,有访问控制、属主、属组等。

图2 HDFS 分布式文件系统
Block Size 属性表示HDFS的块大小,由于Hadoop的优点是大数据处理,当处理TB、PB 级别数据的时候,可以根据需要调节为256M、512M 等。它的配置直接影响了分配给map阶段每个Split的大小,从而影响map过程的效率。配置Block Size 属性,理论上应从以下几点考虑:
第一,GB、TB 级别的大数据处理,分片小了,增加了map过程的开销。
第二,分片大了,负载均衡的效果不理想。
第三,NameNode 的内存压力,随着块大小的增加,NameNode 内存压力变小。
当数据量过大的时候,或者集群规模不大,可选择大一点的分片。3个节点的机群,要处理1GB 的数据,不妨设置分片128M或者256M。实际应用中,分片大小的选取,要从数据量和节点个数考虑。另外,处理小数据量时也不必设置小于64M(比如32M),就如同Windows 下,不必将块大小设置为小于512byte。
Replication 属性配置了数据块的复本数,体现了HDFS 容错机制,一旦有节点意外停机,用户可以从其他节点读取数据块。实验证明,随着Replication 值增加,实际写入的数据量是原数据量的Replication倍,导致HDFS的写速度降低。因此,在不同场合,应对Replication属性有所取舍。
[page] 2.2 map/reduce 程序设计
map/reduce 程序设计的关键,是构建与应用相关的key/value 键值,也就是map函数输出的中间结果。另外,中间结果的优化也影响了数据分析的效率。
map 函数对源数据提取需要分析的字段,过滤无效数据,进行预处理后,交由reduce进行规约。map函数中间输出(key,V),被写入context.reduce 对map的输出context的内容进行归类,同一key 值的(key,V)放在一个列表中生成(key,list(V)),然后对(key,list(V))进行规约Vout=result(list(V)),任务结果为(key,Vout)。map/reduce 伪码如下:
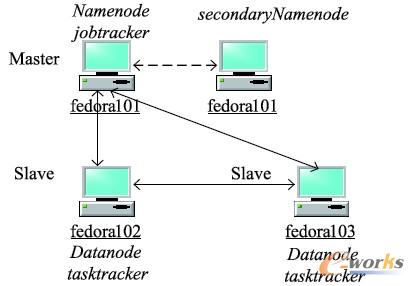
图3 map/reduce 伪码
为了优化map/reduce程序,对map函数的输出在当前节点进行中间处理,然后交予reduce 函数,这种方式称为Hadoop 数据局部性。Hadoop 提供了一个优化数据局部性的函数combiner,实质上combiner 也是一个reduce 规约函数,它不影响reduce 的处理结果。map函数完成,在当前节点进行combiner,实质上是减少了map函数和reduce函数之间的数据传输,因此提高了效率。为此,文献提出了一种改进的数据局部性算法。本实验中,用reduce 函数作为combiner 函数。
3.实验结果
3.1 实验平台
图3,在配置Pentium Dual-core CPU T4300 2。1GHz,4G DDR3 1600mHz 内存,250G WDC ATA 硬盘,32bit-Windows7 sp1 的机器上,运行三台虚拟机fedora101、fedora102、fedora103,操作系统是32 位Fedora Core 15。fedora101 是Master 节点,fedora101、fedora102、fedora103 是Slave 节点。由于实验资源有限,Master 节点fedora101,也运行了 Slave 节点的实例。但是,在实际生产上,尽量避免这样做,不仅Master与Slave 要物理上隔离,SecondaryNameNode 也要与NameNode 隔离。

图4 实验环境系统架构
3.2 实验分析及优化
Hadoop的性能表现在两个方面:一是HDFS 大数据存储的效率;二是map/reduce 程序大数据分析的效率。以此将应用分为载入数据和分析数据两个阶段,这两个阶段的效率直接影响了用户感受。对于云计算来说,影响这两个效率的瓶颈是网络传输效率和磁盘I/O,在网络环境理想的LAN中,暂不予考虑网络传输效率。
HDFS 的Replication 属性很大程度上影响了数据载入效率,是磁盘I/O对性能的影响。它确保了在发生数据块、磁盘、机器故障后数据不丢失。当系统发现一个错误的块,会从其他节点读取另一个复本,保证复本数回到Replication 的值。 当Replication 过大时,会影响写数据的效率,因为数据量比原数据大了Replication 倍,并且在WAN中应考虑网络数据传输的开销。当应用仅仅是为了分析数据时,可以将Replication 设置为1。表2列出了不同Replication 值对HDFS效率的影响。
当数据达到GB规模,内存已不能满足需求,必定有中间数据被写入磁盘等待处理。因此,磁盘I/O的效率直接关系了map/reduce 数据处理的效率。文献和文献给出了两种基于map/reduce 的优化方案,本质是开发基于map/reduce 程序的分类算法,提高数据分析的效率。这两种方法,没有从本质上解决大数据处理所面临的I/O 压力。

表2 Replication 值对HDFS 效率的影响
本文给出了两种优化map/reduce性能的方法。根据对Hadoop系统的研究,提出了数据局部性优化和I/O 缓存优化,本质上都是提高磁盘I/O 性能。数据局部性优化提供combiner函数,减少了map 到reduce的I/O。I/O 缓存优化是配置Hadoop数据I/O缓冲区的大小,从默认的4096字节,增加到65536字节。实验证明,map/reduce 程序性能有了明显提高。表3列出了两种典型的优化方案。
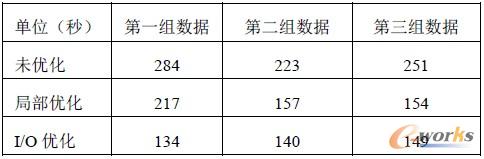
表3 map/reduce 程序处理时间比较
4.结语
本文应用Hadoop云计算模型,提高了数据存储的安全性,数据分析的效率,满足了应用的要求,提供了更好的用户体验。同时,分析了map/reduce计算模型的瓶颈,从而根据应用对环境进行优化,并进行验证,得出map/reduce 程序的优化应从I/O性能着手。实验结果表明,HDFS 文件系统能够很好的容错,map/reduce具有高效的数据分析能力,完全可以替代传统的单机的数据存储、分析。今后要实践解决的问题是,如何快速的跨平台向Hadoop提交数据,降低数据移植给Hadoop带来的效率影响。
本文的局限性在于资源有限,只能构建虚拟集群,有构成规模。所以,要验证了Hadoop投入生产使用的可行性,以及在技术上遇到的问题,通过优化系统配置和程序代码,提高数据分析的效率。
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




